
Quick Start
Types and Values
Variables
Variables are immutable by default. Use mut keyword to allow changes.
fn main() {
let x:i32 = 10;
println!("x: {x}");
// error[E0384]: cannot assign twice to immutable variable `x`
// x = 20;
// println!("x: {x}");
// use mut keyword to allow changes
let mut y: i64 = 100;
println!("y: {y}");
y = 200;
println!("y: {y}");
}
Values
| Types | Literals | |
|---|---|---|
| Signed integers | i8, i16, i32, i64, i128, isize | -10, 0, 1_000, 123_i64 |
| Unsigned integers | u8, u16, u32, u64, u128, usize | 0, 123, 10_u16 |
| Floating point numbers | f32, f64 | 3.14, -10.0e20, 2_f32 |
| Unicode scalar values | char | 'a', 'α', '∞' |
| Booleans | bool | true, false |
The types have width as follows:
iN,uN, andfNare N bits wide.isizeandusizeare the width of a pointer,charis 32 bits wide,boolis 8 bits wide.
All underscores in numbers can be left out, they are for legibility only. So 1_000 can be written as 1000 (or 10_00), and 123_i64 can be written as 123i64.
Arithmetic
fn interproduct(a: i32, b: i32, c: i32) -> i32 {
return a * b + b * c + c * a;
}
fn main() {
println!("result: {}", interproduct(120, 100, 248));
}
Change the i32’s to i16 to see an integer overflow, which panics (checked) in a debug build and wraps in a release build. There are other options, such as overflowing, saturating, and carrying. These are accessed with method syntax, e.g., (a * b).saturating_add(b * c).saturating_add(c * a).
In fact, the compiler will detect overflow of constant expressions, which is why the example requires a separate function.
Strings
Rust has two types to represent strings:
String- a modifiable, owned string&str- a read-only string. String literals have this type.
fn main() {
let greeting: &str = "Greetings";
let planet: &str = "🪐";
let mut sentence = String::new();
sentence.push_str(greeting);
sentence.push_str(", ");
sentence.push_str(planet);
println!("final sentence: {}", sentence);
println!("{:?}", &sentence[0..5]);
// println!("{:?}", &sentence[12..13]);
}
Type Inference
fn takes_u32(x: u32) {
println!("u32: {x}");
}
fn takes_i8(y: i8) {
println!("i8: {y}");
}
fn main() {
let x = 10;
let y = 20;
takes_u32(x);
takes_i8(y);
// error[E0308]: mismatched types expected `u32`, found `i8`
// takes_u32(y);
}
When nothing constrains the type of an integer literal, Rust defaults to i32. This sometimes appears as {integer} in error messages. Similarly, floating-point literals default to f64.
Control Flow
if
fn main() {
let x = 10;
if x < 20 {
println!("small");
} else if x < 100 {
println!("biggish");
} else {
println!("huge");
}
// use if as an expression
let size = if x < 20 { "small" } else { "large" };
println!("number size: {}", size);
}
In addition, you can use if as an expression. The last expression of each block becomes the value of the if expression.
Because if is an expression and must have a particular type, both of its branch blocks must have the same type. Show what happens if you add ; after "small" in the second example.
When if is used in an expression, the expression must have a ; to separate it from the next statement. Remove the ; before println! to see the compiler error.
Loops
while
fn main() {
let mut x = 200;
while x >= 10 {
x = x / 2;
}
println!("Final x: {x}");
}
for
fn main() {
for x in 1..5 {
println!("x: {x}");
}
}
loop
fn main() {
let mut i = 0;
loop {
i += 1;
println!("{i}");
if i > 100 {
break;
}
}
}
Use the label to break out of nested loops:
fn main() {
'outer: for x in 1..5 {
println!("x: {x}");
let mut i = 0;
while i < x {
println!("x: {x}, i: {i}");
i += 1;
if i == 3 {
break 'outer;
}
}
}
}
Blocks and Scopes
Blocks
A block in Rust contains a sequence of expressions. Each block has a value and a type, which are those of the last expression of the block:
fn main() {
let z = 13;
let x = {
let y = 10;
println!("y: {y}");
z - y
};
println!("x: {x}");
}
Scopes and Shadowing
fn main() {
let a = 10;
println!("before: {a}");
{
let a = "hello";
println!("inner scope: {a}");
let a = true;
println!("shadowed in inner scope: {a}");
}
println!("after: {a}");
}
Functions
fn gcd(a: u32, b: u32) -> u32 {
if b > 0 {
gcd(b, a % b)
} else {
a
}
}
fn main() {
println!("gcd: {}", gcd(143, 52));
}
- Declaration parameters are followed by a type, then a return type
- The last expression in a function body (or any block) becomes the return value. Simply omit the
;at the end of the expression. Thereturnkeyword can be used for early return, but the “bare value” form is idiomatic at the end of a function (refactorgcdto use areturn). - Overloading is not supported – each function has a single implementation.
- Always takes a fixed number of parameters. Default arguments are not supported. Macros can be used to support variadic functions.
- Always takes a single set of parameter types. These types can be generic, which will be covered later.
Macros
Macros are expanded into Rust code during compilation, and can take a variable number of arguments. They are distinguished by a ! at the end. The Rust standard library includes an assortment of useful macros:
println!(format, ..)prints a line to standard outputformat!(format, ..)works just likeprintln!but returns the result as a string.dbg!(expression)logs the value of the expression and returns it.todo!()marks a bit of code as not-yet-implemented. If executed, it will panic.unreachable!()marks a bit of code as unreachable. If executed, it will panic.
Tuples and Arrays
| Types | Literals | |
|---|---|---|
| Arrays | [T; N] | [20, 30, 40], [0; 3] |
| Tuples | (), (T,), (T1, T2), … | (), ('x',), ('x', 1.2), … |
fn main() {
// array assignment and access
let mut a: [i8; 10] = [42; 10];
a[5] = 0;
println!("a: {a:?}");
println!("a: {a:#?}");
// tuple assignment and access
let t: (i8, bool) = (7, true);
println!("t.0: {}", t.0);
println!("t.1: {}", t.1);
}
- Arrays:
- A value of the array type
[T; N]holdsN(a compile-time constant) elements of the same typeT. Note that the length of the array is part of its type, which means that[u8; 3]and[u8; 4]are considered two different types. - Try accessing an out-of-bounds array element. Array accesses are checked at runtime. Rust can usually optimize these checks away, and they can be avoided using unsafe Rust.
- We can use literals to assign values to arrays.
- The
println!macro asks for the debug implementation with the?format parameter:{}gives the default output,{:?}gives the debug output. Types such as integers and strings implement the default output, but arrays only implement the debug output. This means that we must use debug output here. - Adding
#, eg{a:#?}, invokes a “pretty printing” format, which can be easier to read.
- A value of the array type
- Tuples:
- Have a fixed length.
- Tuples group together values of different types into a compound type.
- Fields of a tuple can be accessed by the period and the index of the value, e.g.
t.0,t.1. - The empty tuple
()is also known as the “unit type”. It is both a type, and the only valid value of that type — that is to say both the type and its value are expressed as(). It is used to indicate, for example, that a function or expression has no return value. You can think of it asvoidthat can be familiar to you from other programming languages.
Array Iteration
fn main() {
let primes = [2, 3, 5, 7, 11, 13, 17, 19];
for prime in primes {
for i in 2..prime {
assert_ne!(prime % i, 0);
}
}
}
The assert_ne! macro is new here. There are also assert_eq! and assert! macros. These are always checked while, debug-only variants like debug_assert! compile to nothing in release builds.
Pattern Matching
The match keyword lets you match a value against one or more patterns. The comparisons are done from top to bottom and the first match wins.
The patterns can be simple values, similarly to switch in C and C++:
fn main() {
let input = 'x';
match input {
'q' => println!("Quitting"),
'a' | 's' | 'w' | 'd' => println!("Moving around"),
'0'..='9' => println!("Number input"),
key if key.is_lowercase() => println!("Lowercase: {key}"),
_ => println!("Something else"),
}
}
The _ pattern is a wildcard pattern which matches any value.
A variable in the pattern (key in this example) will create a binding that can be used within the match arm.
Some specific characters are being used when in a pattern
|as anor..can expand as much as it needs to be1..=5represents an inclusive range_is a wild card
Destructing
Destructuring is a way of extracting data from a data structure by writing a pattern that is matched up to the data structure, binding variables to subcomponents of the data structure.
You can destructure tuples and arrays by matching on their elements:
fn main() {
// tuple
describe_point((1, 0));
// array
match_triple([0, -2, 3]);
}
// destruct tuple
fn describe_point(point: (i32, i32)) {
match point {
(0, _) => println!("on Y axis"),
(_, 0) => println!("on X axis"),
(x, _) if x < 0 => println!("left of Y axis"),
(_, y) if y < 0 => println!("below X axis"),
_ => println!("first quadrant"),
}
}
// destruct array
fn match_triple(triple: [i32; 3]) {
println!("Tell me about {triple:?}");
match triple {
[0, y, z] => println!("First is 0, y = {y}, and z = {z}"),
[1, ..] => println!("First is 1 and the rest were ignored"),
_ => println!("All elements were ignored"),
}
}
References
Shared References
Shared references are read-only, and the referenced data cannot change.
fn main() {
let a = 'A';
let b = 'B';
let mut r: &char = &a;
println!("r: {}", *r);
r = &b;
println!("r: {}", *r);
}
A shared reference to a type T has type &T. A reference value is made with the & operator. The * operator “dereferences” a reference, yielding its value.
Rust will statically forbid dangling references:
fn x_axis(x: i32) -> &(i32, i32) {
let point = (x, 0);
return &point;
}
Exclusive References
Exclusive references, also known as mutable references, allow changing the value they refer to. They have type &mut T.
fn main() {
let mut point = (1, 2);
let x_coord = &mut point.0;
*x_coord = 20;
println!("Point: {point:?}");
}
“Exclusive” means that only this reference can be used to access the value. No other references (shared or exclusive) can exist at the same time, and the referenced value cannot be accessed while the exclusive reference exists.
User Defined Types
struct Person {
name: String,
age: u8,
}
fn describe(person: &Person) {
println!("{} is {} years old", person.name, person.age);
}
fn main() {
let mut peter = Person {
name: String::from("Peter"),
age: 27,
};
describe(&peter);
peter.age = 28;
describe(&peter);
let name = String::from("Avery");
let age = 39;
let avery = Person { name, age };
describe(&avery);
let jackie = Person {
name: String::from("Jackie"),
..avery
};
describe(&jackie);
}
- Zero-sized structs (e.g.
struct Foo;) might be used when implementing a trait on some type but don’t have any data that you want to store in the value itself. - The syntax
..averyallows us to copy the majority of the fields from the old struct without having to explicitly type it all out. It must always be the last element.
Tuple Structs
If the field name are unimportant, you can use a tuple struct:
struct Point(i32, i32);
fn main() {
let p = Point(17, 23);
println!("{}, {}", p.0, p.1);
}
This is often used for single-field wrappers (called newtypes):
struct PoundsOfForce(f64);
struct Newtons(f64);
fn compute_thruster_force() -> PoundsOfForce {
todo!("Ask a rocket scientist at NASA")
}
fn set_thruster_force(force: Newtons) {
// ...
}
fn main() {
let force = compute_thruster_force();
set_thruster_force(force);
}
Enums
The enum keyword allows the creation of a type which has a few different variants:
#[derive(Debug)]
enum Direction {
Left,
// Right,
}
#[derive(Debug)]
enum PlayerMove {
// Pass, // Simple variant
Run(Direction), // Tuple variant
// Teleport { x: u32, y: u32 }, // Struct variant
}
fn main() {
let m: PlayerMove = PlayerMove::Run(Direction::Left);
println!("On this turn: {:?}", m);
}
Enumerations allow you to collect a set of values under one type.
Directionis a type with variants. There are two values ofDirection:Direction::LeftandDirection::Right.PlayerMoveis a type with three variants. In addition to the payloads, Rust will store a discriminant so that it knows at runtime which variant is in aPlayerMovevalue.This might be a good time to compare structs and enums:
- In both, you can have a simple version without fields (unit struct) or one with different types of fields (variant payloads).
- You could even implement the different variants of an enum with separate structs but then they wouldn’t be the same type as they would if they were all defined in an enum.
Rust uses minimal space to store the discriminant.
If necessary, it stores an integer of the smallest required size
If the allowed variant values do not cover all bit patterns, it will use invalid bit patterns to encode the discriminant (the “niche optimization”). For example,
Option<&u8>stores either a pointer to an integer orNULLfor theNonevariant.You can control the discriminant if needed (e.g., for compatibility with C):
#[repr(u32)] enum Bar { A, // 0 B = 10000, C, // 10001 } fn main() { println!("A: {}", Bar::A as u32); println!("B: {}", Bar::B as u32); println!("C: {}", Bar::C as u32); }Without
repr, the discriminant type takes 2 bytes, because 10001 fits 2 bytes.
Static and Const
Static and constant variables are two different ways to create globally-scoped values that cannot be moved or reallocated during the execution of the program.
const
Constant variables are evaluated at compile time and their values are inlined wherever they are used:
const DIGEST_SIZE: usize = 3;
const ZERO: Option<u8> = Some(42);
fn compute_digest(text: &str) -> [u8; DIGEST_SIZE] {
let mut digest = [ZERO.unwrap_or(0); DIGEST_SIZE];
for (idx, &b) in text.as_bytes().iter().enumerate() {
digest[idx % DIGEST_SIZE] = digest[idx % DIGEST_SIZE].wrapping_add(b);
}
digest
}
fn main() {
let digest = compute_digest("Hello");
println!("digest: {digest:?}");
}
Only functions marked const can be called at compile time to generate const values. const functions can however be called at runtime.
static
Static variables will live during the whole execution of the program, and therefore will not move:
static BANNER: &str = "Welcome to RustOS 3.14";
fn main() {
println!("{BANNER}");
}
| Property | Static | Constant |
|---|---|---|
| Has an address in memory | Yes | No (inlined) |
| Lives for the entire duration of the program | Yes | No |
| Can be mutable | Yes (unsafe) | No |
| Evaluated at compile time | Yes (initialised at compile time) | Yes |
| Inlined wherever it is used | No | Yes |
Type Aliases
A type alias creates a name for another type. The two types can be used interchangeably.
enum CarryableConcreteItem {
Left,
Right,
}
type Item = CarryableConcreteItem;
// Aliases are more useful with long, complex types:
use std::{sync::{Arc, RwLock}, cell::RefCell};
type PlayerInventory = RwLock<Vec<Arc<RefCell<Item>>>>;
Pattern Matching
Let Control Flow
Rust has a few control flow constructs which differ from other languages. They are used for pattern matching:
if letexpressionswhile letexpressionsmatchexpressions
let if expression
fn sleep_for(secs: f32) {
let dur = if let Ok(dur) = std::time::Duration::try_from_secs_f32(secs) {
dur
} else {
std::time::Duration::from_millis(500)
};
std::thread::sleep(dur);
println!("slept for {:?}", dur);
}
fn main() {
sleep_for(-10.0);
sleep_for(0.8);
}
- Unlike
match,if letdoes not have to cover all branches. This can make it more concise thanmatch. - A common usage is handling
Somevalues when working withOption. - Unlike
match,if letdoes not support guard clauses for pattern matching.
let else expression
fn hex_or_die_trying(maybe_string: Option<String>) -> Result<u32, String> {
let s = if let Some(s) = maybe_string {
s
} else {
return Err(String::from("got None"));
};
let first_byte_char = if let Some(first_byte_char) = s.chars().next() {
first_byte_char
} else {
return Err(String::from("got empty string"));
};
if let Some(digit) = first_byte_char.to_digit(16) {
Ok(digit)
} else {
Err(String::from("not a hex digit"))
}
}
fn main() {
println!("result: {:?}", hex_or_die_trying(Some(String::from("foo"))));
}
if-lets can pile up, as shown. The let-else construct supports flattening this nested code. Rewrite:
fn hex_or_die_trying(maybe_string: Option<String>) -> Result<u32, String> {
let Some(s) = maybe_string else {
return Err(String::from("got None"));
};
let Some(first_byte_char) = s.chars().next() else {
return Err(String::from("got empty string"));
};
let Some(digit) = first_byte_char.to_digit(16) else {
return Err(String::from("not a hex digit"));
};
return Ok(digit);
}
while let expression
fn main() {
let mut name = String::from("Comprehensive Rust 🦀");
while let Some(c) = name.pop() {
println!("character: {c}");
}
// (There are more efficient ways to reverse a string!)
}
- Point out that the
while letloop will keep going as long as the value matches the pattern. - You could rewrite the
while letloop as an infinite loop with an if statement that breaks when there is no value to unwrap forname.pop(). Thewhile letprovides syntactic sugar for the above scenario.
Methods and Traits
Methods
Rust allows you to associate functions with new types with an impl block:
#[derive(Debug)]
struct Race {
name: String,
laps: Vec<i32>,
}
impl Race {
fn new(name: &str) -> Self {
Self {
name: String::from(name),
laps: Vec::new(),
}
}
// Exclusive borrowed read-write access to self
fn add_lap(&mut self, lap: i32) {
self.laps.push(lap);
}
fn print_laps(&self) {
println!("Recorded {} laps for {}", self.laps.len(), self.name);
for (idx, laps) in self.laps.iter().enumerate() {
println!("Lap {idx}: {laps} sec");
}
}
fn finish(self) {
let total: i32 = self.laps.iter().sum();
println!("Race {} is finished, total lap time: {}", self.name, total);
}
}
fn main() {
let mut race = Race::new("Monaco Grand Prix");
race.add_lap(70);
race.add_lap(68);
race.print_laps();
race.add_lap(71);
race.print_laps();
// note: `Race::finish` takes ownership of the receiver `self`, which moves `race`
// race.add_lap(56);
}
The self arguments specify the “receiver” - the object the method acts on. There are several common receivers for a method:
&self: borrows the object from the caller using a shared and immutable reference. The object can be used again afterwards.&mut self: borrows the object from the caller using a unique and mutable reference. The object can be used again afterwards.self: takes ownership of the object and moves it away from the caller. The method becomes the owner of the object. The object will be dropped (deallocated) when the method returns, unless its ownership is explicitly transmitted. Complete ownership does not automatically mean mutability.mut self: same as above, but the method can mutate the object.- No receiver: this becomes a static method on the struct. Typically used to create constructors which are called
newby convention.
Traits
Rust lets you abstract over types with traits. They’re similar to interfaces:
struct Dog {
name: String,
age: i8,
}
struct Cat {
lives: i8,
}
trait Pet {
fn talk(&self) -> String;
fn greet(&self) {
println!("What's your name? {}", self.talk());
}
}
impl Pet for Dog {
fn talk(&self) -> String {
return format!("Woof, my name is {}", self.name);
}
}
impl Pet for Cat {
fn talk(&self) -> String {
return String::from("WTF?");
}
}
fn main() {
let c = Cat { lives: 9 };
let d = Dog {
name: String::from("Fido"),
age: 5,
};
c.greet();
d.greet();
}
- A trait defines a number of methods that types must have in order to implement the trait.
- Traits are implemented in an
impl <trait> for <type> { .. }block. - Traits may specify pre-implemented (provided) methods and methods that users are required to implement themselves. Provided methods can rely on required methods. In this case,
greetis provided, and relies ontalk.
Deriving
Supported traits can be automatically implemented for your custom types, as follows:
#[derive(Debug, Clone, Default)]
struct Player {
name: String,
strength: u8,
hit_points: u8,
}
fn main() {
let p1 = Player::default();
let mut p2 = p1.clone();
p2.name = String::from("Alice");
println!("{:?} vs. {:?}", p1, p2);
}
Derivation is implemented with macros, and many crates provide useful derive macros to add useful functionality. For example, serde can derive serialization support for a struct using #[derive(Serialize)].
Trait Objects
Trait objects allow for values of different types, for instance in a collection:
struct Dog {
name: String,
age: i8,
}
struct Cat {
lives: i8,
}
trait Pet {
fn talk(&self) -> String;
}
impl Pet for Dog {
fn talk(&self) -> String {
return format!("Woof, my name is {}!", self.name);
}
}
impl Pet for Cat {
fn talk(&self) -> String {
return String::from("WTF!");
}
}
fn main() {
let pets: Vec<Box<dyn Pet>> = vec![
Box::new(Cat { lives: 9 }),
Box::new(Dog {
name: String::from("Fido"),
age: 5,
}),
];
for pet in pets {
println!("Hello, who are you? {}", pet.talk());
}
}
Memory layout after allocating pets:
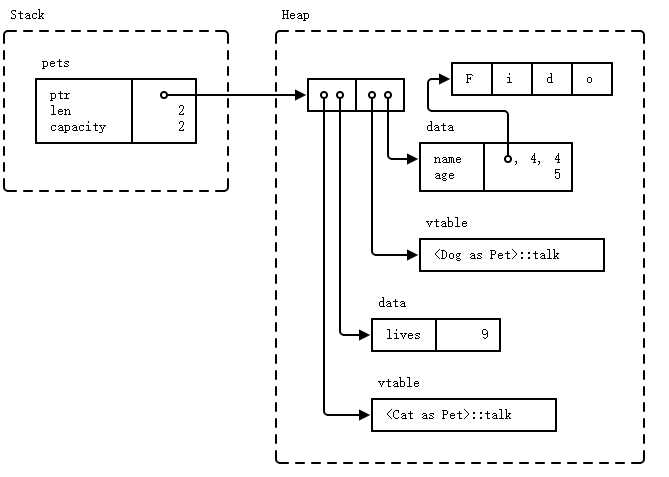
- Types that implement a given trait may be of different sizes. This makes it impossible to have things like
Vec<dyn Pet>in the example above. dyn Petis a way to tell the compiler about a dynamically sized type that implementsPet.- In the example,
petsis allocated on the stack and the vector data is on the heap. The two vector elements are fat pointers:- A fat pointer is a double-width pointer. It has two components: a pointer to the actual object and a pointer to the virtual method table (vtable) for the
Petimplementation of that particular object. - The data for the
Dognamed Fido is thenameandagefields. TheCathas alivesfield.
- A fat pointer is a double-width pointer. It has two components: a pointer to the actual object and a pointer to the virtual method table (vtable) for the
Compare these outputs in the above example:
println!("{} {}", std::mem::size_of::<Dog>(), std::mem::size_of::<Cat>());
println!("{} {}", std::mem::size_of::<&Dog>(), std::mem::size_of::<&Cat>());
println!("{}", std::mem::size_of::<&dyn Pet>());
println!("{}", std::mem::size_of::<Box<dyn Pet>>());
Generics
Generic functions
Rust supports generics, which lets you abstract algorithms or data structures (such as sorting or a binary tree) over the types used or stored.
fn pick<T>(n: i32, even: T, odd: T) -> T {
if n & 1 == 0 {
even
} else {
odd
}
}
fn main() {
println!("picked a number: {:?}", pick(97, 22, 33));
println!("picked a tuple: {:?}", pick(28, ("dog", 1), ("cat", 2)));
}
- Rust infers a type for T based on the types of the arguments and return value.
- This is similar to C++ templates, but Rust partially compiles the generic function immediately, so that function must be valid for all types matching the constraints. For example, try modifying
pickto returneven + oddifn == 0. Even if only thepickinstantiation with integers is used, Rust still considers it invalid. C++ would let you do this. - Generic code is turned into non-generic code based on the call sites. This is a zero-cost abstraction: you get exactly the same result as if you had hand-coded the data structures without the abstraction.
Generic Data Types
You can use generics to abstract over the concrete field type:
#[derive(Debug)]
struct Point<T> {
x: T,
y: T,
}
// impl<T> means methods are defined for any T
// Point<T> means types in Point are defined for any T
impl<T> Point<T> {
fn coords(&self) -> (&T, &T) {
(&self.x, &self.y)
}
}
fn main() {
let integer = Point { x: 5, y: 10 };
let float = Point { x: 1.0, y: 4.0 };
println!("{integer:?} and {float:?}");
println!("coords: {:?}", integer.coords());
}
- Why
Tis specified twice inimpl<T> Point<T> {}? Isn’t that redundant?- This is because it is a generic implementation section for generic type. They are independently generic.
- It means these methods are defined for any
T. - It is possible to write
impl Point<u32> { .. }.Pointis still generic and you can usePoint<f64>, but methods in this block will only be available forPoint<u32>.
Trait Bounds
When working with generics, you often want to require the types to implement some trait, so that you can call this trait’s methods.
You can do this with T: Trait or impl Trait:
fn duplicate<T: Clone>(a: T) -> (T, T) {
(a.clone(), a.clone())
}
fn main() {
let foo = String::from("foo");
let pair = duplicate(foo);
println!("{pair:?}");
}
where clause
fn duplicate<T>(a: T) -> (T, T)
where
T: Clone,
{
(a.clone(), a.clone())
}
- It declutters the function signature if you have many parameters.
- t has additional features making it more powerful. The extra feature is that the type on the left of “:” can be arbitrary, like
Option<T>.
impl Trait
// Syntactic sugar for:
// fn add_42_millions<T: Into<i32>>(x: T) -> i32 {
fn add_42_millions(x: impl Into<i32>) -> i32 {
x.into() + 42_000_000
}
fn pair_of(x: u32) -> impl std::fmt::Debug {
(x + 1, x - 1)
}
fn main() {
let many = add_42_millions(42_i8);
println!("{many}");
let many_more = add_42_millions(10_000_000);
println!("{many_more}");
let debuggable = pair_of(27);
println!("debuggable: {debuggable:?}");
}
impl Trait allows you to work with types which you cannot name. The meaning of impl Trait is a bit different in the different positions.
For a parameter,
impl Traitis like an anonymous generic parameter with a trait bound.For a return type, it means that the return type is some concrete type that implements the trait, without naming the type. This can be useful when you don’t want to expose the concrete type in a public API.
Inference is hard in return position. A function returning
impl Foopicks the concrete type it returns, without writing it out in the source. A function returning a generic type likecollect<B>() -> Bcan return any type satisfyingB, and the caller may need to choose one, such as withlet x: Vec<_> = foo.collect()or with the turbofish,foo.collect::<Vec<_>>().
Standard Library Types
Documentation
ust comes with extensive documentation. For example:
- All of the details about loops.
- Primitive types like
u8. - Standard library types like
OptionorBinaryHeap.
In fact, you can document your own code:
/// Determine whether the first argument is divisible by the second argument.
///
/// If the second argument is zero, the result is false.
fn is_divisible_by(lhs: u32, rhs: u32) -> bool {
if rhs == 0 {
return false;
}
lhs % rhs == 0
}
The contents are treated as Markdown. All published Rust library crates are automatically documented at docs.rs using the rustdoc tool. It is idiomatic to document all public items in an API using this pattern.
To document an item from inside the item (such as inside a module), use //! or /*! .. */, called “inner doc comments”:
//! This module contains functionality relating to divisibility of integers.
Option
It stores either a value of type T or nothing. For example, String::find returns an Option<usize>.
fn main() {
let name = "Löwe 老虎 Léopard Gepardi";
let mut position: Option<usize> = name.find('é');
println!("find returned {position:?}");
assert_eq!(position.unwrap(), 14);
position = name.find('Z');
println!("find returned {position:?}");
assert_eq!(position.expect("Character not found"), 0);
}
Optionis widely used, not just in the standard library.unwrapwill return the value in anOption, or panic.expectis similar but takes an error message.- You can panic on None, but you can’t “accidentally” forget to check for None.
- It’s common to
unwrap/expectall over the place when hacking something together, but production code typically handlesNonein a nicer fashion.
- The niche optimization means that
Option<T>often has the same size in memory asT.
Result
Result is similar to Option, but indicates the success or failure of an operation, each with a different type.
use std::fs::File;
use std::io::Read;
fn main() {
let file: Result<File, std::io::Error> = File::open("diary.txt");
match file {
Ok(mut file) => {
let mut contents = String::new();
if let Ok(bytes) = file.read_to_string(&mut contents) {
println!("Dear diary: {contents} ({bytes} bytes)");
} else {
println!("Could not read file content");
}
},
Err(err) => {
println!("The diary could not be opened: {err}");
}
}
}
- As with
Option, the successful value sits inside ofResult, forcing the developer to explicitly extract it. This encourages error checking. In the case where an error should never happen,unwrap()orexpect()can be called, and this is a signal of the developer intent too. Resultdocumentation is a recommended read. Not during the course, but it is worth mentioning. It contains a lot of convenience methods and functions that help functional-style programming.
String
String is the standard heap-allocated growable UTF-8 string buffer:
fn main() {
let mut s1 = String::new();
s1.push_str("Hello");
println!("s1: len = {}, capacity = {}", s1.len(), s1.capacity());
let mut s2 = String::with_capacity(s1.len() + 1);
s2.push_str(&s1);
s2.push('!');
println!("s2: len = {}, capacity = {}", s2.len(), s2.capacity());
let s3 = String::from("🇨🇭");
println!("s3: len = {}, number of chars = {}", s3.len(),
s3.chars().count());
}
String implements Deref, which means that you can call all str methods on a String.
String::newreturns a new empty string, useString::with_capacitywhen you know how much data you want to push to the string.String::lenreturns the size of theStringin bytes (which can be different from its length in characters).String::charsreturns an iterator over the actual characters. Note that acharcan be different from what a human will consider a “character” due to grapheme clusters.- When people refer to strings they could either be talking about
&strorString. - When a type implements
Deref<Target = T>, the compiler will let you transparently call methods fromT.- We haven’t discussed the
Dereftrait yet, so at this point this mostly explains the structure of the sidebar in the documentation. StringimplementsDeref<Target = str>which transparently gives it access tostr’s methods.- Write and compare
let s3 = s1.deref();andlet s3 = &*s1;.
- We haven’t discussed the
Stringis implemented as a wrapper around a vector of bytes, many of the operations you see supported on vectors are also supported onString, but with some extra guarantees.- Compare the different ways to index a
String:- To a character by using
s3.chars().nth(i).unwrap()whereiis in-bound, out-of-bounds. - To a substring by using
s3[0..4], where that slice is on character boundaries or not.
- To a character by using
Vec
Vec is the standard resizable heap-allocated buffer:
fn main() {
let mut v1 = Vec::new();
v1.push(42);
print_vec(&v1);
let mut v2 = Vec::with_capacity(v1.len() + 1);
v2.extend(v1.iter());
v2.push(999);
print_vec(&v2);
// Canonical marco to initialize a vector with elements
let mut v3 = vec![0, 0, 1, 2, 3];
print_vec(&v3);
// Retain only the even elements.
v3.retain(|x| x & 1 == 0);
print_vec(&v3);
// Remove consecutive duplicates
v3.dedup();
println!("{v3:?}");
}
fn print_vec(v: &Vec<i64>) {
println!("v1: len: {}, cap: {}", v.len(), v.capacity());
}
Vecis a type of collection, along withStringandHashMap. The data it contains is stored on the heap. This means the amount of data doesn’t need to be known at compile time. It can grow or shrink at runtime.- Notice how
Vec<T>is a generic type too, but you don’t have to specifyTexplicitly. As always with Rust type inference, theTwas established during the firstpushcall. vec![...]is a canonical macro to use instead ofVec::new()and it supports adding initial elements to the vector.- To index the vector you use
[], but they will panic if out of bounds. Alternatively, usinggetwill return anOption. Thepopfunction will remove the last element.
HashMap
Standard hash map with protection against HashDoS attacks:
use std::collections::HashMap;
fn main() {
let mut m = HashMap::new();
m.insert("A", 1);
m.insert("B", 2);
m.insert("C", 3);
println!("m: {m:?}");
println!("m contains D: {}", m.contains_key("D"));
println!("m contains A: {}", m.contains_key("A"));
match m.get("A") {
Some(v) => println!("A: {}", v),
None => println!("A is not exists"),
}
// insert a entry with default val when the key is not found
let e = m.entry("D").or_insert(0);
*e += 1;
println!("{e:#?}");
}
HashMapis not defined in the prelude and needs to be brought into scope.since Rust 1.56, HashMap implements [
From<[(K, V); N]>](<https://doc.rust-lang.org/std/collections/hash_map/struct.HashMap.html#impl-From<[(K,+V);+N]>-for-HashMap>), which allows us to easily initialize a hash map from a literal array:let page_counts = HashMap::from([ ("Harry Potter and the Sorcerer's Stone".to_string(), 336), ("The Hunger Games".to_string(), 374), ]);Alternatively HashMap can be built from any
Iteratorwhich yields key-value tuples.
Memory Management
Program Memory
Programs allocate memory in two ways:
- Stack: Continuous area of memory for local variables.
- Values have fixed sizes known at compile time.
- Extremely fast: just move a stack pointer.
- Easy to manage: follows function calls.
- Great memory locality.
- Heap: Storage of values outside of function calls.
- Values have dynamic sizes determined at runtime.
- Slightly slower than the stack: some book-keeping needed.
- No guarantee of memory locality.
Creating a String puts fixed-sized metadata on the stack and dynamically sized data, the actual string, on the heap:
fn main() {
let s1 = String::from("Hello");
}
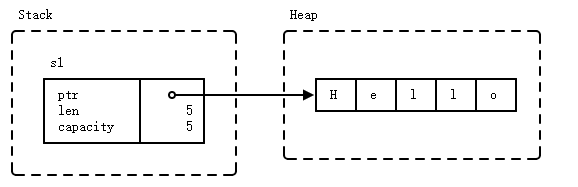
Approaches to Memory Management
Traditionally, languages have fallen into two broad categories:
- Full control via manual memory management: C, C++, Pascal, …
- Programmer decides when to allocate or free heap memory.
- Programmer must determine whether a pointer still points to valid memory.
- Studies show, programmers make mistakes.
- Full safety via automatic memory management at runtime: Java, Python, Go, Haskell, …
- A runtime system ensures that memory is not freed until it can no longer be referenced.
- Typically implemented with reference counting, garbage collection, or RAII.
Rust offers a new mix:
Full control and safety via compile time enforcement of correct memory management.
It does this with an explicit ownership concept.
- C must manage heap manually with
mallocandfree. Common errors include forgetting to callfree, calling it multiple times for the same pointer, or dereferencing a pointer after the memory it points to has been freed. - C++ has tools like smart pointers (
unique_ptr,shared_ptr) that take advantage of language guarantees about calling destructors to ensure memory is freed when a function returns. It is still quite easy to mis-use these tools and create similar bugs to C. - Java, Go, and Python rely on the garbage collector to identify memory that is no longer reachable and discard it. This guarantees that any pointer can be dereferenced, eliminating use-after-free and other classes of bugs. But, GC has a runtime cost and is difficult to tune properly.
Rust’s ownership and borrowing model can, in many cases, get the performance of C, with alloc and free operations precisely where they are required – zero cost. It also provides tools similar to C++’s smart pointers. When required, other options such as reference counting are available, and there are even third-party crates available to support runtime garbage collection (not covered in this class).
Ownership
All variable bindings have a scope where they are valid and it is an error to use a variable outside its scope:
struct Point (i32, i32);
fn main() {
{
let p = Point(3, 4);
println!("x: {}", p.0);
}
// cannot find value `p` in this scope
// println!("y: {}", p.1);
}
We say that the variable owns the value. Every Rust value has precisely one owner at all times.
At the end of the scope, the variable is dropped and the data is freed. A destructor can run here to free up resources.
Move Semantics
An assignment will transfer ownership between variables:
fn main() {
let s1: String = String::from("Hello");
let s2: String = s1;
println!("s2: {s2}");
// borrow of moved value: `s1`
// println!("s1: {s1}");
}
- The assignment of
s1tos2transfers ownership. - When
s1goes out of scope, nothing happens: it does not own anything. - When
s2goes out of scope, the string data is freed.
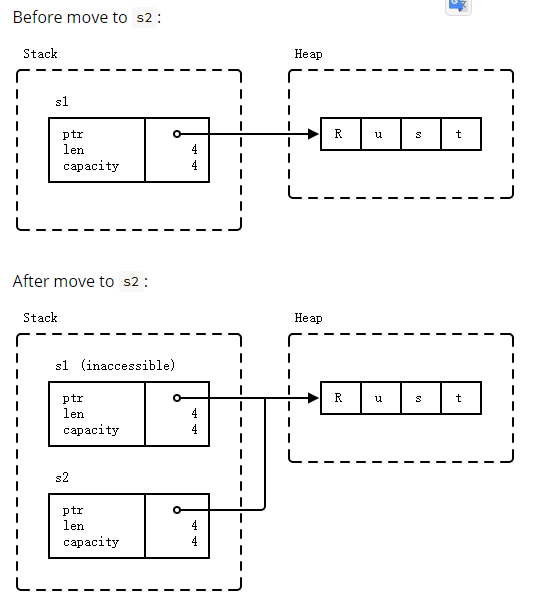
When you pass a value to a function, the value is assigned to the function parameter. This transfers ownership:
fn main() {
let s1: String = String::from("Hello");
let s2: String = s1;
println!("s2: {s2}");
// borrow of moved value: `s1`
// println!("s1: {s1}");
let name = String::from("Alice");
say_hello(name);
// use of moved value: `name`
// say_hello(name);
// pass a clone of name
let name2 = String::from("Alice");
say_hello(name2.clone());
say_hello(name2.clone());
// main func can retain ownership by passing name as reference
let name3 = &String::from("Kesa");
say_hello_ref(name3);
say_hello_ref(name3);
}
fn say_hello(name: String) {
println!("Hello {name}");
}
fn say_hello_ref(name: &String) {
println!("Hello {name}");
}
- With the first call to
say_hello,maingives up ownership ofname. Afterwards,namecannot be used anymore withinmain. - The heap memory allocated for
namewill be freed at the end of thesay_hellofunction. maincan retain ownership if it passesnameas a reference (&name) and ifsay_helloaccepts a reference as a parameter.- In Rust, clones are explicit (by using
clone).maincan pass a clone ofnamein the first call (name.clone()).
Clone
Sometimes you want to make a copy of a value. The Clone trait accomplishes this.
#[derive(Default, Debug)]
struct Backends {
hostnames: Vec<String>,
weights: Vec<f64>,
}
impl Backends {
fn set_hostname(&mut self, hostnames: Vec<String>) {
self.hostnames = hostnames.clone();
self.weights = hostnames.iter().map(|_| 1.0).collect();
}
}
Copy Types
While move semantics are the default, certain types are copied by default:
fn main() {
let x = 42;
let y = x;
println!("x: {x}"); // would not be accessible if not Copy
println!("y: {y}");
}
These types implement the Copy trait.
You can opt-in your own types to use copy semantics:
#[derive(Copy, Clone, Debug)]
struct Point(i32, i32);
fn main() {
let p1 = Point(3, 4);
let p2 = p1; // call p1.clone implicitly
println!("p1: {p1:?}");
println!("p2: {p2:?}");
}
- After the assignment, both
p1andp2own their own data. - We can also use
p1.clone()to explicitly copy the data.
Copying and cloning are not the same thing:
- Copying refers to bitwise copies of memory regions and does not work on arbitrary objects.
- Copying does not allow for custom logic (unlike copy constructors in C++).
- Cloning is a more general operation and also allows for custom behavior by implementing the
Clonetrait. - Copying does not work on types that implement the
Droptrait.
The Drop Trait
Values which implement Drop can specify code to run when they go out of scope:
struct Droppable {
name: &'static str,
}
impl Drop for Droppable {
fn drop(&mut self) {
println!("Dropping {}", self.name);
}
}
fn main() {
let a = Droppable { name: "a" };
{
let b = Droppable { name: "b" };
{
let c = Droppable { name: "c" };
let d = Droppable { name: "d" };
println!("Exiting block B");
}
println!("Exiting block A");
}
drop(a);
println!("Exiting block main");
}
Ouput:
Exiting block B
Dropping d
Dropping c
Exiting block A
Dropping b
Dropping a
Exiting block main
- Note that
std::mem::dropis not the same asstd::ops::Drop::drop. - Values are automatically dropped when they go out of scope.
- When a value is dropped, if it implements
std::ops::Dropthen itsDrop::dropimplementation will be called. - All its fields will then be dropped too, whether or not it implements
Drop. std::mem::dropis just an empty function that takes any value. The significance is that it takes ownership of the value, so at the end of its scope it gets dropped. This makes it a convenient way to explicitly drop values earlier than they would otherwise go out of scope.- This can be useful for objects that do some work on
drop: releasing locks, closing files, etc.
- This can be useful for objects that do some work on
Why doesn’t
Drop::droptakeself?If it did,
std::mem::dropwould be called at the end of the block, resulting in another call toDrop::drop, and a stack overflow!
Smart Pointers
Box
Box is an owned pointer to data on the heap:
fn main() {
let five = Box::new(5);
println!("five: {}", *five);
}
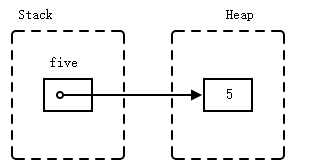
Box<T> implements Deref<Target = T>, which means that you can call methods from T directly on a Box.
Recursive data types or data types with dynamic sizes need to use a Box:
#[derive(Debug)]
enum List<T> {
/// A non-empty list, consisting of the first element and the rest of the list.
Element(T, Box<List<T>>),
/// An empty list.
Nil,
}
fn main() {
let list: List<i32> = List::Element(1, Box::new(List::Element(2, Box::new(List::Nil))));
println!("{list:?}");
}
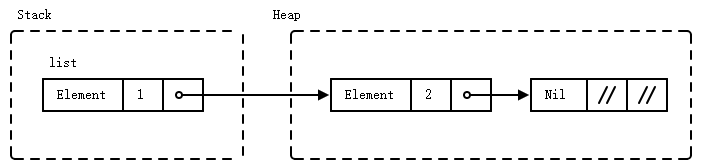
Boxis likestd::unique_ptrin C++, except that it’s guaranteed to be not null.- A
Boxcan be useful when you:- have a type whose size that can’t be known at compile time, but the Rust compiler wants to know an exact size.
- want to transfer ownership of a large amount of data. To avoid copying large amounts of data on the stack, instead store the data on the heap in a
Boxso only the pointer is moved.
- If
Boxwas not used and we attempted to embed aListdirectly into theList, the compiler would not compute a fixed size of the struct in memory (Listwould be of infinite size). Boxsolves this problem as it has the same size as a regular pointer and just points at the next element of theListin the heap.- Remove the
Boxin the List definition and show the compiler error. “Recursive with indirection” is a hint you might want to use a Box or reference of some kind, instead of storing a value directly.
Niche Optimization
#[derive(Debug)]
enum List<T> {
Element(T, Box<List<T>>),
Nil,
}
fn main() {
let list: List<i32> = List::Element(1, Box::new(List::Element(2, Box::new(List::Nil))));
println!("{list:?}");
}
A Box cannot be empty, so the pointer is always valid and non-null. This allows the compiler to optimize the memory layout:
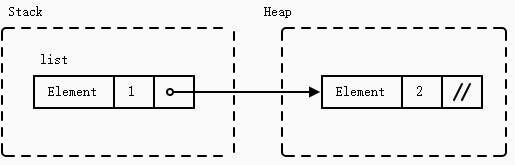
Rc
Rc is a reference-counted shared pointer. Use this when you need to refer to the same data from multiple places:
use std::rc::Rc;
fn main() {
let a = Rc::new(10);
let b = Rc::clone(&a);
println!("a: {a}");
println!("b: {b}");
}
Rc’s count ensures that its contained value is valid for as long as there are references.Rcin Rust is likestd::shared_ptrin C++.Rc::cloneis cheap: it creates a pointer to the same allocation and increases the reference count. Does not make a deep clone and can generally be ignored when looking for performance issues in code.make_mutactually clones the inner value if necessary (“clone-on-write”) and returns a mutable reference.- Use
Rc::strong_countto check the reference count. Rc::downgradegives you a weakly reference-counted object to create cycles that will be dropped properly (likely in combination withRefCell).
Borrowing Value
Instead of transferring ownership when calling a function, you can let a function borrow the value:
#[derive(Debug)]
struct Point(i32, i32);
fn add(p1: &Point, p2: &Point) -> Point {
Point(p1.0 + p2.0, p1.1 + p2.1)
}
fn main() {
let p1 = Point(3, 4);
let p2 = Point(10, 20);
let p3 = add(&p1, &p2);
println!("{p1:?} + {p2:?} = {p3:?}");
}
- The
addfunction borrows two points and returns a new point. - The caller retains ownership of the inputs.
Borrow Checking
Rust’s borrow checker puts constraints on the ways you can borrow values. For a given value, at any time:
- You can have one or more shared references to the value, or
- You can have exactly one exclusive reference to the value.
fn main() {
let mut a: i32 = 10;
let b: &i32 = &a;
{
let c: &mut i32 = &mut a;
*c = 20;
}
println!("a: {a}");
// cannot borrow `a` as mutable because
// it is also borrowed as immutable
// println!("b: {b}");
}
- Note that the requirement is that conflicting references not exist at the same point. It does not matter where the reference is dereferenced.
- The above code does not compile because
ais borrowed as mutable (throughc) and as immutable (throughb) at the same time. - The exclusive reference constraint is quite strong. Rust uses it to ensure that data races do not occur. Rust also relies on this constraint to optimize code. For example, a value behind a shared reference can be safely cached in a register for the lifetime of that reference.
Interior Mutability
Rust provides a few safe means of modifying a value given only a shared reference to that value. All of these replace compile-time checks with runtime checks.
Cell and RefCell
Cell and RefCell implement what Rust calls interior mutability: mutation of values in an immutable context.
Cell is typically used for simple types, as it requires copying or moving values. More complex interior types typically use RefCell, which tracks shared and exclusive references at runtime and panics if they are misused.
use std::cell::RefCell;
use std::rc::Rc;
#[derive(Debug, Default)]
struct Node {
value: i64,
children: Vec<Rc<RefCell<Node>>>,
}
impl Node {
fn new(value: i64) -> Rc<RefCell<Node>> {
Rc::new(RefCell::new(Node {
value,
..Node::default()
}))
}
fn sum(&self) -> i64 {
self.value + self.children.iter().map(|c| c.borrow().sum()).sum::<i64>()
}
}
fn main() {
let root = Node::new(1);
root.borrow_mut().children.push(Node::new(5));
let subtree = Node::new(10);
subtree.borrow_mut().children.push(Node::new(11));
subtree.borrow_mut().children.push(Node::new(12));
root.borrow_mut().children.push(subtree);
println!("graph: {root:#?}");
println!("graph sum: {}", root.borrow().sum());
}
- If we were using
Cellinstead ofRefCellin this example, we would have to move theNodeout of theRcto push children, then move it back in. This is safe because there’s always one, un-referenced value in the cell, but it’s not ergonomic. - To do anything with a Node, you must call a
RefCellmethod, usuallyborroworborrow_mut.
Slices
A slice gives you a view into a larger collection:
fn main() {
let mut a: [i32; 6] = [10, 20, 30, 40, 50, 60];
println!("a: {a:?}");
let s: &[i32] = &a[2..4];
// cannot assign to `a[_]` because it is borrowed
// a[3] = 400;
println!("s: {s:?}");
a[3] = 400;
println!("a: {a:?}");
}
- Slices borrow data from the sliced type.
- We create a slice by borrowing
aand specifying the starting and ending indexes in brackets. - If the slice starts at index 0, Rust’s range syntax allows us to drop the starting index, meaning that
&a[0..a.len()]and&a[..a.len()]are identical. - The same is true for the last index, so
&a[2..a.len()]and&a[2..]are identical. - To easily create a slice of the full array, we can therefore use
&a[..]. sis a reference to a slice ofi32s. Notice that the type ofs(&[i32]) no longer mentions the array length. This allows us to perform computation on slices of different sizes.- Slices always borrow from another object. In this example,
ahas to remain ‘alive’ (in scope) for at least as long as our slice. - You cannot modify the
a[3]before printingsfor memory safety reasons you cannot do it throughaat this point in the execution, but you can read the data from bothaandssafely. It works before you created the slice, and again after theprintln, when the slice is no longer used.
String Reference
&str is almost like &[char], but with its data stored in a variable-length encoding (UTF-8).
fn main() {
let s1: &str = "World";
println!("s1: {s1}");
let mut s2: String = String::from("Hello");
println!("s2: {s2}");
s2.push_str(s1);
println!("s2: {s2}");
let s3: &str = &s2[6..];
println!("s3: {s3}");
}
&stran immutable reference to a string slice.Stringa mutable string buffer.&strintroduces a string slice, which is an immutable reference to UTF-8 encoded string data stored in a block of memory. String literals (”Hello”), are stored in the program’s binary.Rust’s
Stringtype is a wrapper around a vector of bytes. As with aVec<T>, it is owned.As with many other types
String::from()creates a string from a string literal;String::new()creates a new empty string, to which string data can be added using thepush()andpush_str()methods.The
format!()macro is a convenient way to generate an owned string from dynamic values. It accepts the same format specification asprintln!().You can borrow
&strslices fromStringvia&and optionally range selection. If you select a byte range that is not aligned to character boundaries, the expression will panic. Thecharsiterator iterates over characters and is preferred over trying to get character boundaries right.Byte strings literals allow you to create a
&[u8]value directly:fn main() { println!("{:?}", b"abc"); println!("{:?}", &[97, 98, 99]); }
Lifetime Annotations
A reference has a lifetime, which must not “outlive” the value it refers to. This is verified by the borrow checker.
The lifetime can be implicit - this is what we have seen so far. Lifetimes can also be explicit: &'a Point, &'document str. Lifetimes start with ' and 'a is a typical default name. Read &'a Point as “a borrowed Point which is valid for at least the lifetime a”.
Lifetimes are always inferred by the compiler: you cannot assign a lifetime yourself. Explicit lifetime annotations create constraints where there is ambiguity; the compiler verifies that there is a valid solution.
Lifetimes become more complicated when considering passing values to and returning values from functions.
#[derive(Debug)]
struct Point(i32, i32);
fn left_most(p1: &Point, p2: &Point) -> &Point {
if p1.0 < p2.0 { p1 } else { p2 }
}
fn main() {
let p1: Point = Point(10, 10);
let p2: Point = Point(20, 20);
let p3 = left_most(&p1, &p2); // What is the lifetime of p3?
println!("p3: {p3:?}");
}
n this example, the the compiler does not know what lifetime to infer for
p3. Looking inside the function body shows that it can only safely assume thatp3’s lifetime is the shorter ofp1andp2. But just like types, Rust requires explicit annotations of lifetimes on function arguments and return values.Add
'aappropriately toleft_most:fn left_most<'a>(p1: &'a Point, p2: &'a Point) -> &'a Point {his says, “given p1 and p2 which both outlive
'a, the return value lives for at least'a.
Lifetimes in Function Calls
Lifetimes for function arguments and return values must be fully specified, but Rust allows lifetimes to be elided in most cases with a few simple rules. This is not inference – it is just a syntactic shorthand.
- Each argument which does not have a lifetime annotation is given one.
- If there is only one argument lifetime, it is given to all un-annotated return values.
- If there are multiple argument lifetimes, but the first one is for
self, that lifetime is given to all un-annotated return values.
#[derive(Debug)]
struct Point(i32, i32);
fn cab_distance(p1: &Point, p2: &Point) -> i32 {
(p1.0 - p2.0).abs() + (p1.1 - p2.1).abs()
}
fn nearest<'a>(points: &'a [Point], query: &Point) -> Option<&'a Point> {
let mut nearest = None;
for p in points {
if let Some((_, nearest_dist)) = nearest {
let dist = cab_distance(p, query);
if dist < nearest_dist {
nearest = Some((p, dist));
}
} else {
nearest = Some((p, cab_distance(p, query)));
};
}
nearest.map(|(p, _)| p)
}
fn main() {
println!(
"{:?}",
nearest(
&[Point(1, 0), Point(1, 0), Point(-1, 0), Point(0, -1),],
&Point(0, 2)
)
);
}
In this example, cab_distance is trivially elided.
The nearest function provides another example of a function with multiple references in its arguments that requires explicit annotation.
Lifetimes in Data Structures
If a data type stores borrowed data, it must be annotated with a lifetime:
#[derive(Debug)]
struct Highlight<'doc>(&'doc str);
fn erase(text: String) {
println!("Bye {text}!");
}
fn main() {
let text = String::from("The quick brown fox jumps over the lazy dog.");
let fox = Highlight(&text[4..19]);
let dog = Highlight(&text[35..43]);
// erase(text);
println!("{fox:?}");
println!("{dog:?}");
}
- In the above example, the annotation on
Highlightenforces that the data underlying the contained&strlives at least as long as any instance ofHighlightthat uses that data. - If
textis consumed before the end of the lifetime offox(ordog), the borrow checker throws an error. - Types with borrowed data force users to hold on to the original data. This can be useful for creating lightweight views, but it generally makes them somewhat harder to use.
- When possible, make data structures own their data directly.
- Some structs with multiple references inside can have more than one lifetime annotation. This can be necessary if there is a need to describe lifetime relationships between the references themselves, in addition to the lifetime of the struct itself. Those are very advanced use cases.
Iterators
Iterator
The Iterator trait supports iterating over values in a collection. It requires a next method and provides lots of methods. Many standard library types implement Iterator, and you can implement it yourself, too:
struct Fibonacci {
curr: u32,
next: u32,
}
impl Iterator for Fibonacci {
type Item = u32;
fn next(&mut self) -> Option<Self::Item> {
let new_next = self.curr + self.next;
self.curr = self.next;
self.next = new_next;
Some(self.curr)
}
}
fn main() {
let fib = Fibonacci { curr: 0, next: 1 };
for (i, n) in fib.enumerate().take(5) {
println!("fib({i}): {n}");
}
}
- The
Iteratortrait implements many common functional programming operations over collections (e.g.map,filter,reduce, etc). This is the trait where you can find all the documentation about them. In Rust these functions should produce the code as efficient as equivalent imperative implementations. IntoIteratoris the trait that makes for loops work. It is implemented by collection types such asVec<T>and references to them such as&Vec<T>and&[T]. Ranges also implement it. This is why you can iterate over a vector withfor i in some_vec { .. }butsome_vec.next()doesn’t exist.
IntoIterator
The Iterator trait tells you how to iterate once you have created an iterator. The related trait IntoIterator defines how to create an iterator for a type. It is used automatically by the for loop.
struct Grid {
x_coords: Vec<u32>,
y_coords: Vec<u32>,
}
impl IntoIterator for Grid {
type Item = (u32, u32);
type IntoIter = GridIter;
fn into_iter(self) -> GridIter {
GridIter { grid: self, i: 0, j: 0 }
}
}
struct GridIter {
grid: Grid,
i: usize,
j: usize,
}
impl Iterator for GridIter {
type Item = (u32, u32);
fn next(&mut self) -> Option<(u32, u32)> {
if self.i >= self.grid.x_coords.len() {
self.i = 0;
self.j += 1;
if self.j >= self.grid.y_coords.len() {
return None;
}
}
let res = Some((self.grid.x_coords[self.i], self.grid.y_coords[self.j]));
self.i += 1;
res
}
}
fn main() {
let grid = Grid {
x_coords: vec![3, 5, 7, 9],
y_coords: vec![10, 20, 30, 40],
};
for (x, y) in grid {
println!("point = {x}, {y}");
}
}
Every implementation of IntoIterator must declare two types:
Item: the type to iterate over, such asi8,IntoIter: theIteratortype returned by theinto_itermethod.
Note that IntoIter and Item are linked: the iterator must have the same Item type, which means that it returns Option<Item>
The example iterates over all combinations of x and y coordinates.
Try iterating over the grid twice in main. Why does this fail? Note that IntoIterator::into_iter takes ownership of self.
Fix this issue by implementing IntoIterator for &Grid and storing a reference to the Grid in GridIter.
The same problem can occur for standard library types: for e in some_vector will take ownership of some_vector and iterate over owned elements from that vector. Use for e in &some_vector instead, to iterate over references to elements of some_vector.
FromIterator
FromIterator lets you build a collection from an Iterator.
fn main() {
let primes = vec![2, 3, 5, 7];
let prime_squares = primes
.into_iter()
.map(|prime| prime * prime)
.collect::<Vec<_>>();
println!("prime_squares: {prime_squares:?}");
}
fn collect<B>(self) -> B
where
B: FromIterator<Self::Item>,
Self: Sized
There are two ways to specify B for this method:
- With the “turbofish”:
some_iterator.collect::<COLLECTION_TYPE>(), as shown. The_shorthand used here lets Rust infer the type of theVecelements. - With type inference:
let prime_squares: Vec<_> = some_iterator.collect(). Rewrite the example to use this form.
There are basic implementations of FromIterator for Vec, HashMap, etc. There are also more specialized implementations which let you do cool things like convert an Iterator<Item = Result<V, E>> into a Result<Vec<V>, E>.
Modules
mod lets us namespace types and functions:
mod foo {
pub fn do_something() {
println!("In the foo module");
}
}
mod bar {
pub fn do_something() {
println!("In the bar module");
}
}
fn main() {
foo::do_something();
bar::do_something();
}
- Packages provide functionality and include a
Cargo.tomlfile that describes how to build a bundle of 1+ crates. - Crates are a tree of modules, where a binary crate creates an executable and a library crate compiles to a library.
- Modules define organization, scope, and are the focus of this section.
Filesystem Hierarchy
Omitting the module content will tell Rust to look for it in another file:
mod garden;
This tells rust that the garden module content is found at src/garden.rs. Similarly, a garden::vegetables module can be found at src/garden/vegetables.rs.
The crate root is in:
src/lib.rs(for a library crate)src/main.rs(for a binary crate)
Modules defined in files can be documented, too, using “inner doc comments”. These document the item that contains them – in this case, a module.
//! This module implements the garden, including a highly performant germination
//! implementation.
// Re-export types from this module.
pub use seeds::SeedPacket;
pub use garden::Garden;
/// Sow the given seed packets.
pub fn sow(seeds: Vec<SeedPacket>) { todo!() }
/// Harvest the produce in the garden that is ready.
pub fn harvest(garden: &mut Garden) { todo!() }
Deeper nesting can use folders, even if the main module is a file:
src/ ├── main.rs ├── top_module.rs └── top_module/ └── sub_module.rsThe place rust will look for modules can be changed with a compiler directive:
#[path = "some/path.rs"] mod some_module;This is useful, for example, if you would like to place tests for a module in a file named
some_module_test.rs, similar to the convention in Go.
Visibility
Modules are a privacy boundary:
- Module items are private by default (hides implementation details).
- Parent and sibling items are always visible.
- In other words, if an item is visible in module
foo, it’s visible in all the descendants offoo.
mod outer {
fn private() {
println!("outer::private");
}
pub fn public() {
println!("outer::public");
}
mod inner {
fn private() {
println!("outer::inner::private");
}
pub fn public() {
println!("outer::inner::public");
super::private();
}
}
}
fn main() {
outer::public();
}
- Use the
pubkeyword to make modules public.
Additionally, there are advanced pub(...) specifiers to restrict the scope of public visibility.
- See the Rust Reference.
- Configuring
pub(crate)visibility is a common pattern. - Less commonly, you can give visibility to a specific path.
- In any case, visibility must be granted to an ancestor module (and all of its descendants).
use, super, self
A module can bring symbols from another module into scope with use. You will typically see something like this at the top of each module:
use std::collections::HashSet;
use std::process::abort;
Paths
Paths are resolved as follows:
- As a relative path:
fooorself::foorefers tofooin the current module,super::foorefers tofooin the parent module.
- As an absolute path:
crate::foorefers tofooin the root of the current crate,bar::foorefers tofooin thebarcrate.
It is common to “re-export” symbols at a shorter path. For example, the top-level lib.rs in a crate might have:
mod storage;
pub use storage::disk::DiskStorage;
pub use storage::network::NetworkStorage;
making DiskStorage and NetworkStorage available to other crates with a convenient, short path.
- For the most part, only items that appear in a module need to be
use’d. However, a trait must be in scope to call any methods on that trait, even if a type implementing that trait is already in scope. For example, to use theread_to_stringmethod on a type implementing theReadtrait, you need touse std::io::Read. - The
usestatement can have a wildcard:use std::io::*. This is discouraged because it is not clear which items are imported, and those might change over time.
Tests
Unit Test
Rust and Cargo come with a simple unit test framework:
- Unit tests are supported throughout your code.
- Integration tests are supported via the
tests/directory.
Tests are marked with #[test]. Unit tests are often put in a nested tests module, using #[cfg(test)] to conditionally compile them only when building tests.
fn first_word(text: &str) -> &str {
match text.find(' ') {
Some(idx) => &text[..idx],
None => &text,
}
}
#[cfg(test)]
mod test {
use super::*;
#[test]
fn test_empty() {
assert_eq!(first_word(""), "");
}
#[test]
fn test_single_word() {
assert_eq!(first_word("Hello"), "Hello");
}
#[test]
fn test_multiple_words() {
assert_eq!(first_word("Hello World"), "Hello");
}
}
- This lets you unit test private helpers.
- The
#[cfg(test)]attribute is only active when you runcargo test.
Integration Tests
If you want to test your library as a client, use an integration test.
Create a .rs file under tests/:
// tests/my_library.rs
use my_library::init;
#[test]
fn test_init() {
assert!(init().is_ok());
}
These tests only have access to the public API of your crate.
Documentation Tests
Rust has built-in support for documentation tests:
/// Shortens a string to the given length.
///
/// ```
/// # use playground::shorten_string;
/// assert_eq!(shorten_string("Hello World", 5), "Hello");
/// assert_eq!(shorten_string("Hello World", 20), "Hello World");
/// ```
pub fn shorten_string(s: &str, length: usize) -> &str {
&s[..std::cmp::min(length, s.len())]
}
- Code blocks in
///comments are automatically seen as Rust code. - The code will be compiled and executed as part of
cargo test. - Adding
#in the code will hide it from the docs, but will still compile/run it.
Mock
For mocking, Mockall is a widely used library. You need to refactor your code to use traits, which you can then quickly mock:
use std::time::Duration;
#[mockall::automock]
pub trait Pet {
fn is_hungry(&self, since_last_meal: Duration) -> bool;
}
#[test]
fn test_robot_dog() {
let mut mock_dog = MockPet::new();
mock_dog.expect_is_hungry().return_const(true);
assert_eq!(mock_dog.is_hungry(Duration::from_secs(10)), true);
}
Error Handling
Rust handles fatal errors with a “panic”.
Rust will trigger a panic if a fatal error happens at runtime:
fn main() {
let v = vec![10, 20, 30];
println!("v[100]: {}", v[100]);
}
- Panics are for unrecoverable and unexpected errors.
- Panics are symptoms of bugs in the program.
- Runtime failures like failed bounds checks can panic
- Assertions (such as
assert!) panic on failure - Purpose-specific panics can use the
panic!macro.
- A panic will “unwind” the stack, dropping values just as if the functions had returned.
- Use non-panicking APIs (such as
Vec::get) if crashing is not acceptable.
By default, a panic will cause the stack to unwind. The unwinding can be caught:
use std::panic;
fn main() {
let result = panic::catch_unwind(|| {
"No problem here!"
});
println!("{result:?}");
let result = panic::catch_unwind(|| {
panic!("oh no!");
});
println!("{result:?}");
}
- Catching is unusual; do not attempt to implement exceptions with
catch_unwind! - This can be useful in servers which should keep running even if a single request crashes.
- This does not work if
panic = 'abort'is set in yourCargo.toml.
Try Operator
Runtime errors like connection-refused or file-not-found are handled with the Result type, but matching this type on every call can be cumbersome. The try-operator ? is used to return errors to the caller. It lets you turn the common
match some_expression {
Ok(value) => value,
Err(err) => return Err(err),
}
into the much simpler
some_expression?
We can use this to simplify our error handling code:
use std::{fs, io};
use std::io::Read;
fn read_username(path: &str) -> Result<String, io::Error> {
let username_file_result = fs::File::open(path);
let mut username_file = match username_file_result {
Ok(file) => file,
Err(err) => return Err(err),
};
let mut username = String::new();
match username_file.read_to_string(&mut username) {
Ok(_) => Ok(username),
Err(err) => Err(err),
}
}
fn main() {
//fs::write("config.dat", "alice").unwrap();
let username = read_username("config.dat");
println!("username or error: {username:?}");
}
Try Conversions
The effective expansion of ? is a little more complicated than previously indicated:
expression?
works the same as
match expression {
Ok(value) => value,
Err(err) => return Err(From::from(err)),
}
The From::from call here means we attempt to convert the error type to the type returned by the function. This makes it easy to encapsulate errors into higher-level errors.
use std::error::Error;
use std::fmt::{self, Display, Formatter};
use std::fs::File;
use std::io::{self, Read};
#[derive(Debug)]
enum ReadUsernameError {
IoError(io::Error),
EmptyUsername(String),
}
impl Error for ReadUsernameError {}
impl Display for ReadUsernameError {
fn fmt(&self, f: &mut Formatter) -> fmt::Result {
match self {
Self::IoError(e) => write!(f, "IO error: {e}"),
Self::EmptyUsername(filename) => write!(f, "Found no username in {filename}"),
}
}
}
impl From<io::Error> for ReadUsernameError {
fn from(err: io::Error) -> Self {
Self::IoError(err)
}
}
fn read_username(path: &str) -> Result<String, ReadUsernameError> {
let mut username = String::with_capacity(100);
File::open(path)?.read_to_string(&mut username)?;
if username.is_empty() {
return Err(ReadUsernameError::EmptyUsername(String::from(path)));
}
Ok(username)
}
fn main() {
//fs::write("config.dat", "").unwrap();
let username = read_username("config.dat");
println!("username or error: {username:?}");
}
The ? operator must return a value compatible with the return type of the function. For Result, it means that the error types have to be compatible. A function that returns Result<T, ErrorOuter> can only use ? on a value of type Result<U, ErrorInner> if ErrorOuter and ErrorInner are the same type or if ErrorOuter implements From<ErrorInner>.
A common alternative to a From implementation is Result::map_err, especially when the conversion only happens in one place.
There is no compatibility requirement for Option. A function returning Option<T> can use the ? operator on Option<U> for arbitrary T and U types.
A function that returns Result cannot use ? on Option and vice versa. However, Option::ok_or converts Option to Result whereas Result::ok turns Result into Option.
Dynamic Error Types
Sometimes we want to allow any type of error to be returned without writing our own enum covering all the different possibilities. The std::error::Error trait makes it easy to create a trait object that can contain any error.
use std::error::Error;
use std::fs;
use std::io::Read;
fn read_count(path: &str) -> Result<i32, Box<dyn Error>> {
let mut count_str = String::new();
fs::File::open(path)?.read_to_string(&mut count_str)?;
let count: i32 = count_str.parse()?;
Ok(count)
}
fn main() {
fs::write("count.dat", "1i3").unwrap();
match read_count("count.dat") {
Ok(count) => println!("Count: {count}"),
Err(err) => println!("Error: {err}"),
}
}
The read_count function can return std::io::Error (from file operations) or std::num::ParseIntError (from String::parse).
Boxing errors saves on code, but gives up the ability to cleanly handle different error cases differently in the program. As such it’s generally not a good idea to use Box<dyn Error> in the public API of a library, but it can be a good option in a program where you just want to display the error message somewhere.
Make sure to implement the std::error::Error trait when defining a custom error type so it can be boxed. But if you need to support the no_std attribute, keep in mind that the std::error::Error trait is currently compatible with no_std in nightly only.
thiserror and anyhow
The thiserror and anyhow crates are widely used to simplify error handling. thiserror helps create custom error types that implement From<T>. anyhow helps with error handling in functions, including adding contextual information to your errors.
use anyhow::{bail, Context, Result};
use std::{fs, io::Read};
use thiserror::Error;
#[derive(Clone, Debug, Eq, Error, PartialEq)]
#[error("Found no username in {0}")]
struct EmptyUsernameError(String);
fn read_username(path: &str) -> Result<String> {
let mut username = String::with_capacity(100);
fs::File::open(path)
.with_context(|| format!("Failed to open {path}"))?
.read_to_string(&mut username)
.context("Failed to read")?;
if username.is_empty() {
bail!(EmptyUsernameError(path.to_string()));
}
Ok(username)
}
fn main() {
//fs::write("config.dat", "").unwrap();
match read_username("config.dat") {
Ok(username) => println!("Username: {username}"),
Err(err) => println!("Error: {err:?}"),
}
}
Concurrency
Rust threads work similarly to threads in other languages:
use std::thread;
use std::time::Duration;
fn main() {
thread::spawn(|| {
for i in 1..10 {
println!("Count in thread: {i}!");
thread::sleep(Duration::from_millis(5));
}
});
for i in 1..5 {
println!("Main thread: {i}");
thread::sleep(Duration::from_millis(5));
}
}
Threads are all daemon threads, the main thread does not wait for them.
Thread panics are independent of each other.
- Panics can carry a payload, which can be unpacked with
downcast_ref.
- Panics can carry a payload, which can be unpacked with
Notice that the thread is stopped before it reaches 10 — the main thread is not waiting.
Use
let handle = thread::spawn(...)and laterhandle.join()to wait for the thread to finish.Trigger a panic in the thread, notice how this doesn’t affect
main.Use the
Resultreturn value fromhandle.join()to get access to the panic payload.
Scoped Threads
Normal threads cannot borrow from their environment:
use std::thread;
fn foo() {
let s = String::from("Hello");
thread::spawn(|| {
println!("Length: {}", s.len());
});
}
fn main() {
foo();
}
However, you can use a scoped thread for this:
use std::thread;
fn main() {
let s = String::from("Hello");
thread::scope(|scope| {
scope.spawn(|| {
println!("Length: {}", s.len());
});
});
}
- The reason for that is that when the
thread::scopefunction completes, all the threads are guaranteed to be joined, so they can return borrowed data. - Normal Rust borrowing rules apply: you can either borrow mutably by one thread, or immutably by any number of threads.
Channels
Rust channels have two parts: a Sender<T> and a Receiver<T>. The two parts are connected via the channel, but you only see the end-points.
use std::sync::mpsc;
fn main() {
let (tx, rx) = mpsc::channel();
tx.send(10).unwrap();
tx.send(20).unwrap();
println!("Received: {:?}", rx.recv());
println!("Received: {:?}", rx.recv());
let tx2 = tx.clone();
tx2.send(30).unwrap();
println!("Received: {:?}", rx.recv());
}
mpscstands for Multi-Producer, Single-Consumer.SenderandSyncSenderimplementClone(so you can make multiple producers) butReceiverdoes not.send()andrecv()returnResult. If they returnErr, it means the counterpartSenderorReceiveris dropped and the channel is closed.
Unbounded Channels
You get an unbounded and asynchronous channel with mpsc::channel():
use std::sync::mpsc;
use std::thread;
use std::time::Duration;
fn main() {
let (tx, rx) = mpsc::channel();
thread::spawn(move || {
let thread_id = thread::current().id();
for i in 1..10 {
tx.send(format!("Message {i}")).unwrap();
println!("{thread_id:?}: sent Message {i}");
}
println!("{thread_id:?}: done");
});
thread::sleep(Duration::from_millis(100));
for msg in rx.iter() {
println!("Main: got {msg}");
}
}
Bounded Channels
With bounded (synchronous) channels, send can block the current thread:
use std::sync::mpsc;
use std::thread;
use std::time::Duration;
fn main() {
let (tx, rx) = mpsc::sync_channel(3);
thread::spawn(move || {
let thread_id = thread::current().id();
for i in 1..10 {
tx.send(format!("Message {i}")).unwrap();
println!("{thread_id:?}: sent Message {i}");
}
println!("{thread_id:?}: done");
});
thread::sleep(Duration::from_millis(100));
for msg in rx.iter() {
println!("Main: got {msg}");
}
}
- Calling
sendwill block the current thread until there is space in the channel for the new message. The thread can be blocked indefinitely if there is nobody who reads from the channel. - A call to
sendwill abort with an error (that is why it returnsResult) if the channel is closed. A channel is closed when the receiver is dropped. - A bounded channel with a size of zero is called a “rendezvous channel”. Every send will block the current thread until another thread calls
read.
Send and Sync
How does Rust know to forbid shared access across threads? The answer is in two traits:
Send: a typeTisSendif it is safe to move aTacross a thread boundary.Sync: a typeTisSyncif it is safe to move a&Tacross a thread boundary.
Send and Sync are unsafe traits. The compiler will automatically derive them for your types as long as they only contain Send and Sync types. You can also implement them manually when you know it is valid.
Send
A type T is Send if it is safe to move a T value to another thread.
The effect of moving ownership to another thread is that destructors will run in that thread. So the question is when you can allocate a value in one thread and deallocate it in another.
Sync
A type T is Sync if it is safe to access a T value from multiple threads at the same time.
More precisely, the definition is:
T` is `Sync` if and only if `&T` is `Send
This statement is essentially a shorthand way of saying that if a type is thread-safe for shared use, it is also thread-safe to pass references of it across threads.
This is because if a type is Sync it means that it can be shared across multiple threads without the risk of data races or other synchronization issues, so it is safe to move it to another thread. A reference to the type is also safe to move to another thread, because the data it references can be accessed from any thread safely.
Shared State
Arc
Arc allows shared read-only access via Arc::clone:
use std::thread;
use std::sync::Arc;
fn main() {
let v = Arc::new(vec![10, 20, 30]);
let mut handles = Vec::new();
for _ in 1..5 {
let v = Arc::clone(&v);
handles.push(thread::spawn(move || {
let thread_id = thread::current().id();
println!("{thread_id:?}: {v:?}");
}));
}
handles.into_iter().for_each(|h| h.join().unwrap());
println!("v: {v:?}");
}
Arcstands for “Atomic Reference Counted”, a thread safe version ofRcthat uses atomic operations.Arc<T>implementsClonewhether or notTdoes. It implementsSendandSyncif and only ifTimplements them both.Arc::clone()has the cost of atomic operations that get executed, but after that the use of theTis free.- Beware of reference cycles,
Arcdoes not use a garbage collector to detect them.std::sync::Weakcan help.
Mutex
Mutex ensures mutual exclusion and allows mutable access to T behind a read-only interface:
use std::sync::Mutex;
fn main() {
let v = Mutex::new(vec![10, 20, 30]);
println!("v: {:?}", v.lock().unwrap());
{
let mut guard = v.lock().unwrap();
guard.push(40);
}
println!("v: {:?}", v.lock().unwrap());
}
Notice how we have a impl Sync for Mutex blanket implementation.
Mutexin Rust looks like a collection with just one element — the protected data.- It is not possible to forget to acquire the mutex before accessing the protected data.
- You can get an
&mut Tfrom an&Mutex<T>by taking the lock. TheMutexGuardensures that the&mut Tdoesn’t outlive the lock being held. Mutex<T>implements bothSendandSynciff (if and only if)TimplementsSend.- A read-write lock counterpart:
RwLock.
Async
use futures::executor::block_on;
async fn count_to(count: i32) {
for i in 1..=count {
println!("Count is: {i}!");
}
}
async fn async_main(count: i32) {
count_to(count).await;
}
fn main() {
block_on(async_main(10));
}
- Note that this is a simplified example to show the syntax. There is no long running operation or any real concurrency in it!
- What is the return type of an async call?
- Use
let future: () = async_main(10);inmainto see the type.
- Use
- The “async” keyword is syntactic sugar. The compiler replaces the return type with a future.
- You cannot make
mainasync, without additional instructions to the compiler on how to use the returned future. - You need an executor to run async code.
block_onblocks the current thread until the provided future has run to completion. .awaitasynchronously waits for the completion of another operation. Unlikeblock_on,.awaitdoesn’t block the current thread..awaitcan only be used inside anasyncfunction (or block; these are introduced later).
Futures
Future is a trait, implemented by objects that represent an operation that may not be complete yet. A future can be polled, and poll returns a Poll.
use std::pin::Pin;
use std::task::Context;
pub trait Future {
type Output;
fn poll(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output>;
}
pub enum Poll<T> {
Ready(T),
Pending,
}
An async function returns an impl Future. It’s also possible (but uncommon) to implement Future for your own types. For example, the JoinHandle returned from tokio::spawn implements Future to allow joining to it.
The .await keyword, applied to a Future, causes the current async function to pause until that Future is ready, and then evaluates to its output.
- he
FutureandPolltypes are implemented exactly as shown; click the links to show the implementations in the docs. - We will not get to
PinandContext, as we will focus on writing async code, rather than building new async primitives. Briefly:Contextallows a Future to schedule itself to be polled again when an event occurs.Pinensures that the Future isn’t moved in memory, so that pointers into that future remain valid. This is required to allow references to remain valid after an.await.
Runtimes
A runtime provides support for performing operations asynchronously (a reactor) and is responsible for executing futures (an executor). Rust does not have a “built-in” runtime, but several options are available:
- Tokio: performant, with a well-developed ecosystem of functionality like Hyper for HTTP or Tonic for gRPC.
- async-std: aims to be a “std for async”, and includes a basic runtime in
async::task. - smol: simple and lightweight
Several larger applications have their own runtimes. For example, Fuchsia already has one.
Tokio
Tokio provides:
- A multi-threaded runtime for executing asynchronous code.
- An asynchronous version of the standard library.
- A large ecosystem of libraries.
use tokio::time;
async fn count_to(count: i32) {
for i in 1..=count {
println!("Count in task: {i}!");
time::sleep(time::Duration::from_millis(5)).await;
}
}
#[tokio::main]
async fn main() {
tokio::spawn(count_to(10));
for i in 1..5 {
println!("Main task: {i}");
time::sleep(time::Duration::from_millis(5)).await;
}
}
Tasks
Rust has a task system, which is a form of lightweight threading.
A task has a single top-level future which the executor polls to make progress. That future may have one or more nested futures that its poll method polls, corresponding loosely to a call stack. Concurrency within a task is possible by polling multiple child futures, such as racing a timer and an I/O operation.
use tokio::io::{self, AsyncReadExt, AsyncWriteExt};
use tokio::net::TcpListener;
#[tokio::main]
async fn main() -> io::Result<()> {
let listener = TcpListener::bind("127.0.0.1:6142").await?;
println!("listening on port 6142");
loop {
let (mut socket, addr) = listener.accept().await?;
println!("connection from {addr:?}");
tokio::spawn(async move {
if let Err(e) = socket.write_all(b"Who are you?\n").await {
println!("socket error: {e:?}");
return;
}
let mut buf = vec![0; 1024];
let reply = match socket.read(&mut buf).await {
Ok(n) => {
let name = std::str::from_utf8(&buf[..n]).unwrap().trim();
format!("Thanks for dialing in, {name}!\n")
}
Err(e) => {
println!("socket error: {e:?}");
return;
}
};
if let Err(e) = socket.write_all(reply.as_bytes()).await {
println!("socket error: {e:?}");
}
});
}
}
Async Channels
Several crates have support for asynchronous channels. For instance tokio:
use tokio::sync::mpsc::{self, Receiver};
async fn ping_handler(mut input: Receiver<()>) {
let mut count: usize = 0;
while let Some(_) = input.recv().await {
count += 1;
println!("Received {count} pings so far.");
}
println!("ping_handler complete");
}
#[tokio::main]
async fn main() {
let (sender, receiver) = mpsc::channel(32);
let ping_handler_task = tokio::spawn(ping_handler(receiver));
for i in 0..10 {
sender.send(()).await.expect("Failed to send ping.");
println!("Sent {} pings so far.", i + 1);
}
drop(sender);
ping_handler_task.await.expect("Something went wrong in ping handler task.");
}
Futures Control Flow
Futures can be combined together to produce concurrent compute flow graphs. We have already seen tasks, that function as independent threads of execution.
Join
A join operation waits until all of a set of futures are ready, and returns a collection of their results. This is similar to Promise.all in JavaScript or asyncio.gather in Python.
use anyhow::Result;
use futures::future;
use reqwest;
use std::collections::HashMap;
async fn size_of_page(url: &str) -> Result<usize> {
let resp = reqwest::get(url).await?;
Ok(resp.text().await?.len())
}
#[tokio::main]
async fn main() {
let urls: [&str; 4] = [
"https://google.com",
"https://httpbin.org/ip",
"https://play.rust-lang.org/",
"BAD_URL",
];
let futures_iter = urls.into_iter().map(size_of_page);
let results = future::join_all(futures_iter).await;
let page_sizes_dict: HashMap<&str, Result<usize>> =
urls.into_iter().zip(results.into_iter()).collect();
println!("{:?}", page_sizes_dict);
}
Select
A select operation waits until any of a set of futures is ready, and responds to that future’s result. In JavaScript, this is similar to Promise.race. In Python, it compares to asyncio.wait(task_set, return_when=asyncio.FIRST_COMPLETED).
Similar to a match statement, the body of select! has a number of arms, each of the form pattern = future => statement. When the future is ready, the statement is executed with the variables in pattern bound to the future’s result.
use tokio::sync::mpsc::{self, Receiver};
use tokio::time::{sleep, Duration};
#[derive(Debug, PartialEq)]
enum Animal {
Cat { name: String },
Dog { name: String },
}
async fn first_animal_to_finish_race(
mut cat_rcv: Receiver<String>,
mut dog_rcv: Receiver<String>,
) -> Option<Animal> {
tokio::select! {
cat_name = cat_rcv.recv() => Some(Animal::Cat { name: cat_name? }),
dog_name = dog_rcv.recv() => Some(Animal::Dog { name: dog_name? })
}
}
#[tokio::main]
async fn main() {
let (cat_sender, cat_receiver) = mpsc::channel(32);
let (dog_sender, dog_receiver) = mpsc::channel(32);
tokio::spawn(async move {
sleep(Duration::from_millis(500)).await;
cat_sender
.send(String::from("Felix"))
.await
.expect("Failed to send cat.");
});
tokio::spawn(async move {
sleep(Duration::from_millis(50)).await;
dog_sender
.send(String::from("Rex"))
.await
.expect("Failed to send dog.");
});
let winner = first_animal_to_finish_race(cat_receiver, dog_receiver)
.await
.expect("Failed to receive winner");
println!("Winner is {winner:?}");
}
Pitfalls of async/await
Blocking the executor
Most async runtimes only allow IO tasks to run concurrently. This means that CPU blocking tasks will block the executor and prevent other tasks from being executed. An easy workaround is to use async equivalent methods where possible.
use futures::future::join_all;
use std::time::Instant;
async fn sleep_ms(start: &Instant, id: u64, duration_ms: u64) {
std::thread::sleep(std::time::Duration::from_millis(duration_ms));
println!(
"future {id} slept for {duration_ms}ms, finished after {}ms",
start.elapsed().as_millis()
);
}
#[tokio::main(flavor = "current_thread")]
async fn main() {
let start = Instant::now();
let sleep_futures = (1..=10).map(|t| sleep_ms(&start, t, t * 10));
join_all(sleep_futures).await;
}
Pin
When you await a future, all local variables (that would ordinarily be stored on a stack frame) are instead stored in the Future for the current async block. If your future has pointers to data on the stack, those pointers might get invalidated. This is unsafe.
Therefore, you must guarantee that the addresses your future points to don’t change. That is why we need to “pin” futures. Using the same future repeatedly in a select! often leads to issues with pinned values.
use tokio::sync::{mpsc, oneshot};
use tokio::task::spawn;
use tokio::time::{sleep, Duration};
// A work item. In this case, just sleep for the given time and respond
// with a message on the `respond_on` channel.
#[derive(Debug)]
struct Work {
input: u32,
respond_on: oneshot::Sender<u32>,
}
// A worker which listens for work on a queue and performs it.
async fn worker(mut work_queue: mpsc::Receiver<Work>) {
let mut iterations = 0;
loop {
tokio::select! {
Some(work) = work_queue.recv() => {
sleep(Duration::from_millis(10)).await; // Pretend to work.
work.respond_on
.send(work.input * 1000)
.expect("failed to send response");
iterations += 1;
}
// TODO: report number of iterations every 100ms
}
}
}
// A requester which requests work and waits for it to complete.
async fn do_work(work_queue: &mpsc::Sender<Work>, input: u32) -> u32 {
let (tx, rx) = oneshot::channel();
work_queue
.send(Work {
input,
respond_on: tx,
})
.await
.expect("failed to send on work queue");
rx.await.expect("failed waiting for response")
}
#[tokio::main]
async fn main() {
let (tx, rx) = mpsc::channel(10);
spawn(worker(rx));
for i in 0..100 {
let resp = do_work(&tx, i).await;
println!("work result for iteration {i}: {resp}");
}
}
Async Traits
Async methods in traits are not yet supported in the stable channel (An experimental feature exists in nightly and should be stabilized in the mid term.)
The crate async_trait provides a workaround through a macro:
use async_trait::async_trait;
use std::time::Instant;
use tokio::time::{sleep, Duration};
#[async_trait]
trait Sleeper {
async fn sleep(&self);
}
struct FixedSleeper {
sleep_ms: u64,
}
#[async_trait]
impl Sleeper for FixedSleeper {
async fn sleep(&self) {
sleep(Duration::from_millis(self.sleep_ms)).await;
}
}
async fn run_all_sleepers_multiple_times(sleepers: Vec<Box<dyn Sleeper>>, n_times: usize) {
for _ in 0..n_times {
println!("running all sleepers..");
for sleeper in &sleepers {
let start = Instant::now();
sleeper.sleep().await;
println!("slept for {}ms", start.elapsed().as_millis());
}
}
}
#[tokio::main]
async fn main() {
let sleepers: Vec<Box<dyn Sleeper>> = vec![
Box::new(FixedSleeper { sleep_ms: 50 }),
Box::new(FixedSleeper { sleep_ms: 100 }),
];
run_all_sleepers_multiple_times(sleepers, 5).await;
}
Cancellation
Dropping a future implies it can never be polled again. This is called cancellation and it can occur at any await point. Care is needed to ensure the system works correctly even when futures are cancelled. For example, it shouldn’t deadlock or lose data.
use std::io::{self, ErrorKind};
use std::time::Duration;
use tokio::io::{AsyncReadExt, AsyncWriteExt, DuplexStream};
struct LinesReader {
stream: DuplexStream,
}
impl LinesReader {
fn new(stream: DuplexStream) -> Self {
Self { stream }
}
async fn next(&mut self) -> io::Result<Option<String>> {
let mut bytes = Vec::new();
let mut buf = [0];
while self.stream.read(&mut buf[..]).await? != 0 {
bytes.push(buf[0]);
if buf[0] == b'\n' {
break;
}
}
if bytes.is_empty() {
return Ok(None)
}
let s = String::from_utf8(bytes)
.map_err(|_| io::Error::new(ErrorKind::InvalidData, "not UTF-8"))?;
Ok(Some(s))
}
}
async fn slow_copy(source: String, mut dest: DuplexStream) -> std::io::Result<()> {
for b in source.bytes() {
dest.write_u8(b).await?;
tokio::time::sleep(Duration::from_millis(10)).await
}
Ok(())
}
#[tokio::main]
async fn main() -> std::io::Result<()> {
let (client, server) = tokio::io::duplex(5);
let handle = tokio::spawn(slow_copy("hi\nthere\n".to_owned(), client));
let mut lines = LinesReader::new(server);
let mut interval = tokio::time::interval(Duration::from_millis(60));
loop {
tokio::select! {
_ = interval.tick() => println!("tick!"),
line = lines.next() => if let Some(l) = line? {
print!("{}", l)
} else {
break
},
}
}
handle.await.unwrap()?;
Ok(())
}