
4.1 函数调用
4.1.1 调用惯例
C
使用 gcc或者 clang 将 C 语言编译成汇编代码是分析其调用惯例的最好方法,从汇编语言中可以了解函数调用的具体过程。
以gcc编译器为例(备注:我用的是windows的版本,原书使用linux):

C代码如下:
int my_function(int arg1, int arg2) {
return arg1 + arg2;
}
int main() {
int i = my_function(1, 2);
}
编译之后:
main:
pushq %rbp
movq %rsp, %rbp
subq $16, %rsp
movl $2, %esi // 设置第二个参数
movl $1, %edi // 设置第一个参数
call my_function
movl %eax, -4(%rbp)
my_function:
pushq %rbp
movq %rsp, %rbp
movl %edi, -4(%rbp) // 取出第一个参数,放到栈上
movl %esi, -8(%rbp) // 取出第二个参数,放到栈上
movl -8(%rbp), %eax // eax = esi = 1
movl -4(%rbp), %edx // edx = edi = 2
addl %edx, %eax // eax = eax + edx = 1 + 2 = 3
popq %rbp
由上可以看出调用过程如下:
- 在
my_function调用前,调用方main函数将my_function的两个参数分别存到 edi 和 esi 寄存器中 - 在
my_function调用时,它会将寄存器 edi 和 esi 中的数据存储到 eax 和 edx 两个寄存器中,随后通过汇编指令addl计算两个入参之和 - 在
my_function调用后,使用寄存器 eax 传递返回值,main函数将my_function的返回值存储到栈上的i变量中
若将参数增加到8个:
int my_function(int arg1, int arg2, int ... arg8) {
return arg1 + arg2 + ... + arg8;
}
得到的汇编代码会发生改变:
main:
pushq %rbp
movq %rsp, %rbp
subq $16, %rsp // 为参数传递申请 16 字节的栈空间
movl $8, 8(%rsp) // 传递第 8 个参数
movl $7, (%rsp) // 传递第 7 个参数
movl $6, %r9d
movl $5, %r8d
movl $4, %ecx
movl $3, %edx
movl $2, %esi
movl $1, %edi
call my_function
main 函数调用 my_function 时,前六个参数会使用 edi、esi、edx、ecx、r8d 和 r9d 六个寄存器传递。
寄存器的使用顺序也是调用惯例的一部分,函数的第一个参数一定会使用 edi 寄存器,第二个参数使用 esi 寄存器,以此类推。
可以看到第7,8个参数没有使用寄存器来存储,而是使用栈:
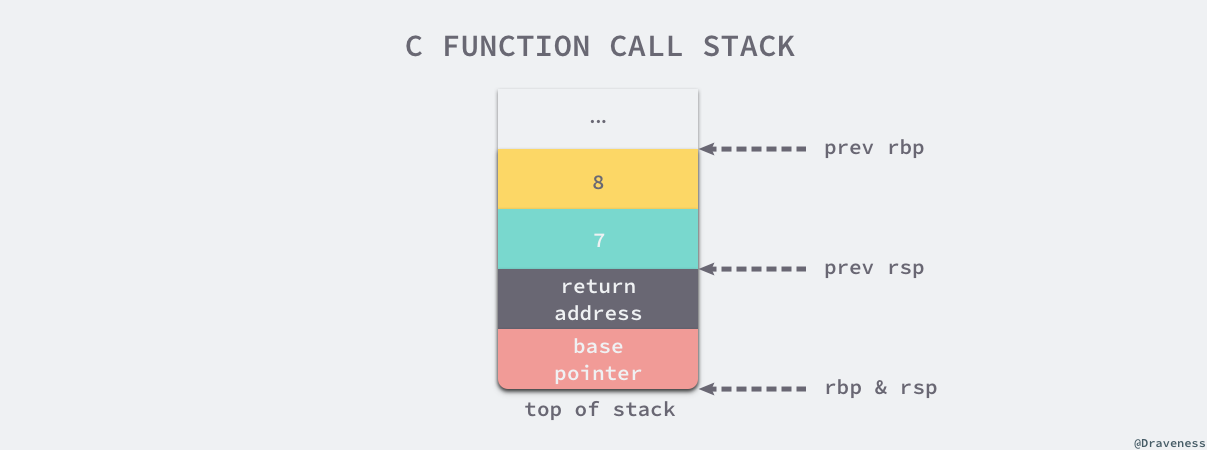
上图中 rbp 寄存器会存储函数调用栈的基址指针,即属于 main 函数的栈空间的起始位置,而另一个寄存器 rsp 存储的是 main 函数调用栈结束的位置,这两个寄存器共同表示了函数的栈空间。
在调用 my_function 之前,main 函数通过 subq $16, %rsp 指令分配了 16 个字节的栈地址,随后将第六个以上的参数按照从右到左的顺序存入栈中,即第八个和第七个,余下的六个参数会通过寄存器传递,接下来运行的 call my_function 指令会调用
my_function 函数:
my_function:
pushq %rbp
movq %rsp, %rbp
movl %edi, -4(%rbp) // rbp-4 = edi = 1
movl %esi, -8(%rbp) // rbp-8 = esi = 2
...
movl -8(%rbp), %eax // eax = 2
movl -4(%rbp), %edx // edx = 1
addl %eax, %edx // edx = eax + edx = 3
...
movl 16(%rbp), %eax // eax = 7
addl %eax, %edx // edx = eax + edx = 28
movl 24(%rbp), %eax // eax = 8
addl %edx, %eax // edx = eax + edx = 36
popq %rbp
综上所述,C语言的函数调用参数都是通过寄存器和栈来传递的:
- 参数个数小于等于 6 个,会按照顺序使用寄存器edi、esi、edx、ecx、r8d 和 r9d传递参数
- 参数个数大于 6个,超过 6 个的部分将会通过从右至左的顺序入栈
函数的返回值是通过寄存器 eax传递的,因为只使用了一个寄存器存储返回值,所以C的函数不能同时返回多个值。
Go
package main
func myFunction(a, b int) (int, int) {
return a + b, a - b
}
func main() {
myFunction(66, 77)
}
使用go tool compile -S -N -l main.go(若不使用-N -l编译器会进行优化,代码有很大差别,-N disable optimizations,禁用优化,-l disable inlining;编译出来的main.o无法直接阅读,需要使用go tool objdump main.o转化成可读文本)
"".main STEXT size=68 args=0x0 locals=0x28
(main.go:7) MOVQ (TLS), CX
(main.go:7) CMPQ SP, 16(CX)
(main.go:7) JLS 61
(main.go:7) SUBQ $40, SP // 分配 40 字节栈空间
(main.go:7) MOVQ BP, 32(SP) // 将基址指针存储到栈上
(main.go:7) LEAQ 32(SP), BP
(main.go:8) MOVQ $66, (SP) // 第一个参数
(main.go:8) MOVQ $77, 8(SP) // 第二个参数
(main.go:8) CALL "".myFunction(SB)
(main.go:9) MOVQ 32(SP), BP
(main.go:9) ADDQ $40, SP
(main.go:9) RET
由上可以得出main 函数调用 myFunction 之前的栈

main 函数通过 SUBQ $40, SP 指令一共在栈上分配了 40 字节的内存空间:
| 空间 | 大小 | 作用 |
|---|---|---|
| SP+32 ~ BP | 8 字节 | main 函数的栈基址指针 |
| SP+16 ~ SP+32 | 16 字节 | 函数 myFunction 的两个返回值 |
| SP ~ SP+16 | 16 字节 | 函数 myFunction 的两个参数 |
Go 的函数参数也是从右到左入栈,之后调用汇编指令 CALL "".myFunction(SB),这个指令首先会将 main 的返回地址存入栈中,然后改变当前的栈指针 SP 并执行 myFunction 的汇编指令:
"".myFunction STEXT nosplit size=49 args=0x20 locals=0x0
(main.go:3) MOVQ $0, "".~r2+24(SP) // 初始化第一个返回值
(main.go:3) MOVQ $0, "".~r3+32(SP) // 初始化第二个返回值
(main.go:4) MOVQ "".a+8(SP), AX // AX = 66
(main.go:4) ADDQ "".b+16(SP), AX // AX = AX + 77 = 143
(main.go:4) MOVQ AX, "".~r2+24(SP) // (24)SP = AX = 143
(main.go:4) MOVQ "".a+8(SP), AX // AX = 66
(main.go:4) SUBQ "".b+16(SP), AX // AX = AX - 77 = -11
(main.go:4) MOVQ AX, "".~r3+32(SP) // (32)SP = AX = -11
(main.go:4) RET
当前函数在执行时首先会将 main 函数中预留的两个返回值地址置成 int 类型的默认值 0,然后根据栈的相对位置获取参数并进行加减操作并将值存回栈中,在 myFunction 函数返回之间,栈中的数据如下图所示:

在 myFunction 返回后,main 函数会通过以下的指令来恢复栈基址指针并销毁已经失去作用的 40 字节栈内存:
(main.go:9) MOVQ 32(SP), BP
(main.go:9) ADDQ $40, SP
(main.go:9) RET
两种方式的对比
C 语言和 Go 语言在设计函数的调用惯例时选择了不同的实现:
- C 同时使用寄存器和栈传递参数,使用 eax 寄存器传递返回值
- Go 使用栈传递参数和返回值
这两种设计的优点和缺点:
- C 语言的方式能够极大地减少函数调用的额外开销,但是也增加了实现的复杂度;
- CPU 访问栈的开销比访问寄存器高几十倍;
- 需要单独处理函数参数过多的情况;
- Go 语言的方式能够降低实现的复杂度并支持多返回值,但是牺牲了函数调用的性能;
- 不需要考虑超过寄存器数量的参数应该如何传递;
- 不需要考虑不同架构上的寄存器差异;
- 函数入参和出参的内存空间需要在栈上进行分配;
4.1.2 参数传递
不同的语言函数参数传递选择的方案不同,一般分为两种:
- 传值:函数调用时会对参数进行拷贝,调用方和被调用方持有不相关的两份数据
- 传引用:函数调用传递参数的指针,被调用方和调用方对数据的更改会相互影响
Golang 中的函数只有值传递的方式,无论是传递基本类型、结构体还是指针,都会对传递的参数进行拷贝。
整型和数组
func myFunction(i int, arr [2]int) {
fmt.Printf("in my_funciton - i=(%d, %p) arr=(%v, %p)\n", i, &i, arr, &arr)
}
func main() {
i := 30
arr := [2]int{66, 77}
fmt.Printf("before calling - i=(%d, %p) arr=(%v, %p)\n", i, &i, arr, &arr)
myFunction(i, arr)
fmt.Printf("after calling - i=(%d, %p) arr=(%v, %p)\n", i, &i, arr, &arr)
}
$ go run main.go
before calling - i=(30, 0xc00001c0b8) arr=([66 77], 0xc00001c0d0)
in my_funciton - i=(30, 0xc00001c100) arr=([66 77], 0xc00001c110)
after calling - i=(30, 0xc00001c0b8) arr=([66 77], 0xc00001c0d0)
若在函数中修改参数的值:
func myFunction(i int, arr [2]int) {
i = 29
arr[1] = 88
fmt.Printf("in my_funciton - i=(%d, %p) arr=(%v, %p)\n", i, &i, arr, &arr)
}
$ go run main.go
before calling - i=(30, 0xc00001c0b8) arr=([66 77], 0xc00001c0d0)
in my_funciton - i=(29, 0xc00001c100) arr=([66 88], 0xc00001c110)
after calling - i=(30, 0xc00001c0b8) arr=([66 77], 0xc00001c0d0)
综上可以看出,Go 语言的整型和数组类型都是值传递的。
若数组非常的大,那么会对性能造成影响。
结构体和指针
type MyStruct struct {
i int
}
func myFunction(a MyStruct, b *MyStruct) {
a.i = 31
b.i = 41
fmt.Printf("in my_function - a=(%d, %p) b=(%v, %p)\n", a, &a, b, &b)
}
func main() {
a := MyStruct{i: 30}
b := &MyStruct{i: 40}
fmt.Printf("before calling - a=(%d, %p) b=(%v, %p)\n", a, &a, b, &b)
myFunction(a, b)
fmt.Printf("after calling - a=(%d, %p) b=(%v, %p)\n", a, &a, b, &b)
}
before calling - a=({30}, 0xc00001c0b8) b=(&{40}, 0xc00000a028)
in my_function - a=({31}, 0xc00001c0f0) b=(&{41}, 0xc00000a038)
after calling - a=({30}, 0xc00001c0b8) b=(&{41}, 0xc00000a028)
可以看出:
- 传递结构体时,拷贝结构体的所有内容
- 传递结构体的指针时,拷贝结构体的指针
因为结构体在内存中是连续的,修改代码简单分析结构体的内存布局:
func myFunc(ms *MyStruct) {
ptr := unsafe.Pointer(ms)
for i := 0; i < 2; i++ {
// 指针移动
c := (*int)(unsafe.Pointer(uintptr(ptr) + uintptr(8*i)))
*c += i + 1
fmt.Printf("[%p] %d\n", c, *c)
}
}
func main() {
ms := &MyStruct{i: 10, j: 20}
myFunc(ms)
fmt.Printf("[%p] %+v", ms, *ms)
}
[0xc00001c0d0] 11
[0xc00001c0d8] 22
[0xc00001c0d0] {i:11 j:22}
上述代码:
- 获取变量
ms的指针 - 将
ms指针转换成*int型,此时指针指向第一个字段i - 再将指针移动 8 个字节(因为操作系统64位,int 型8个字节),此时指向第二个字段
若将其编译成汇编:
main.go:8 0xd26 48c7042400000000 MOVQ $0x0, 0(SP)
main.go:9 0xd2e 488b442418 MOVQ 0x18(SP), AX
main.go:9 0xd33 48890424 MOVQ AX, 0(SP)
main.go:9 0xd37 488b6c2408 MOVQ 0x8(SP), BP
main.go:9 0xd3c 4883c410 ADDQ $0x10, SP
main.go:9 0xd40 c3 RET
当参数是指针时,复制引用,然后将复制后的指针作为返回值传递回调用方。
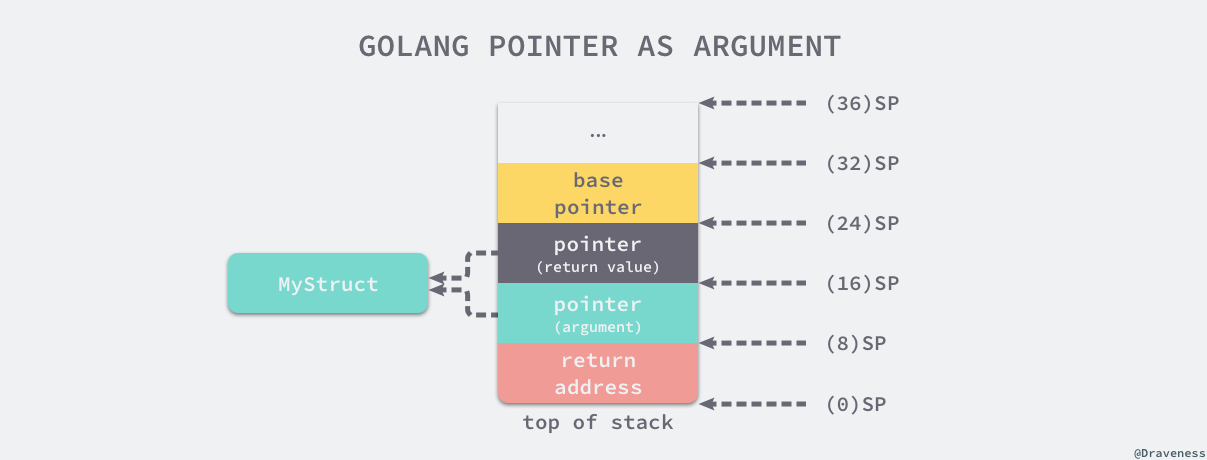
综上,对于结构体和指针都是值传递的形式。
所以在面对比较大的数组或结构体时,应使用指针作为函数参数,避免出现数据拷贝而影响性能。
4.1.3 小结
Golang 的函数调用:
- 函数参数按照从右至左的顺序入栈
- 函数的返回值通过栈传递,并由调用者预先分配空间
- 函数的参数都是值传递,函数参数会进行复制