第三章笔记总结
1. 数组
1.1 定义
数组是由相同类型的元素组成的数据结构,使用一块连续的内存来保存数据。
1.2 类型
Golang 数组的类型包含两点:
- 数组长度
- 元素类型
只有两者相同才是同一类型,例:
[2]int [3]int // 不是同一类型
[2]int [2]interface{} // 不是同一类型
1.3 初始化
使用字面量有两种初始化方式:
- 显式,指定数组长度,如:
[2]int{1, 2, 3},[2]int{} - 隐式,不指定数组长度,使用
[...],如:[...]int{1,2,3}
1.3.1 上限推导
编译期会对隐式初始化进行上限推导,并转化成显式的初始化。
1.3.2 语句转换
根据元素数量不同,编译器做出不同的优化,在不考虑内存逃逸的情况下:
元素数量小于等于 4,直接将数组放入栈上 ; 此时会将字面量转化成更原始的语句,:
// [3]int{1,2,3} var arr [3]int arr[0] = 1 arr[1] = 2 arr[2] = 3元素数量大于 4,在静态存储区初始化数组,并将临时变量赋值给数组,即拷贝到栈上; 伪代码如下:
var arr [5]int statictmp_0[0] = 1 statictmp_0[1] = 2 statictmp_0[2] = 3 statictmp_0[3] = 4 statictmp_0[4] = 5 arr = statictmp_0
1.4 访问和赋值
1.4.1 数组越界
Golang 数组越界检查会有两种情况:
- 编译期检查,当使用字面量或常量访问数组时进行检查 越界则在编译期报错
- 运行时检查,当使用变量访问数组时进行检查 越界则会触发panic
1.4.2 赋值
流程:
- 确定目标数组内存地址
- 获取目标元素内存地址
- 将数据存入地址中
SSA 代码示例:
b1:
...
v21 (5) = LocalAddr <*[3]int> {arr} v2 v19 // 获取数组地址
v22 (5) = PtrIndex <*int> v21 v13 // 获取元素地址
v23 (5) = Store <mem> {int} v22 v20 v19 // 存储数据
...
2. 切片
2.1 定义
A slice, on the other hand, is a dynamically-sized, flexible view into the elements of an array.
2.2 类型
切片的类型只和元素类型有关,例如:
[]int
[]interface{}
2.3 数据结构
编译期和运行时结构不同:
编译期,
cmd/compile/internal/types.Slice:type Slice struct { Elem *Type // element type }运行时,
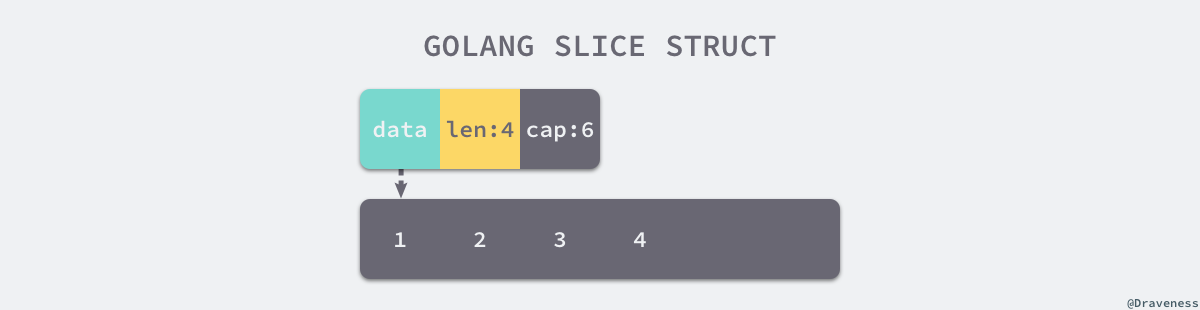
reflect.SliceHeader:type SliceHeader struct { Data uintptr Len int Cap int }Data: 指向数组的指针Len:长度Cap:容量,Data表示的数组的大小
内存示意图:
2.4 初始化
初始化方式有三种:
通过下标获取数组或切片的一部分(Reslice)
arr := [5]{1,2,3,4,5} s1 := arr[1:5] s2 := s1[0:2]初始化时,不会拷贝数组的数据,只会创建新的切片指向原数据;修改新切片和原切片/数组的修改会相互影响
字面量,例如:
[]int{1, 2, 3},会展开成如下所示的代码段:var vstat [3]int vstat[0] = 1 vstat[1] = 2 vstat[2] = 3 var vauto *[3]int = new([3]int) *vauto = vstat slice := vauto[:]最终会通过方式 1),进行初始化
make 关键字,
make(slice_type, len, cap),首先检查传入的长度和容量是否合法,之后根据不同情况进行处理:切片不会发生内存逃逸,且比较小,会转换成如下代码:
var arr [4]int n := arr[:3]将使用方式 1) 进行初始化
切片发生内存逃逸,或者比较大时将在堆上初始化 计算切片所需的内存大小并为其申请一片连续内存
2.5 访问
对于访问的元素或切片的长度和容量,若能够在编译期确认,则直接获取元素地址或直接获取长度和容量。
2.6 追加和扩容
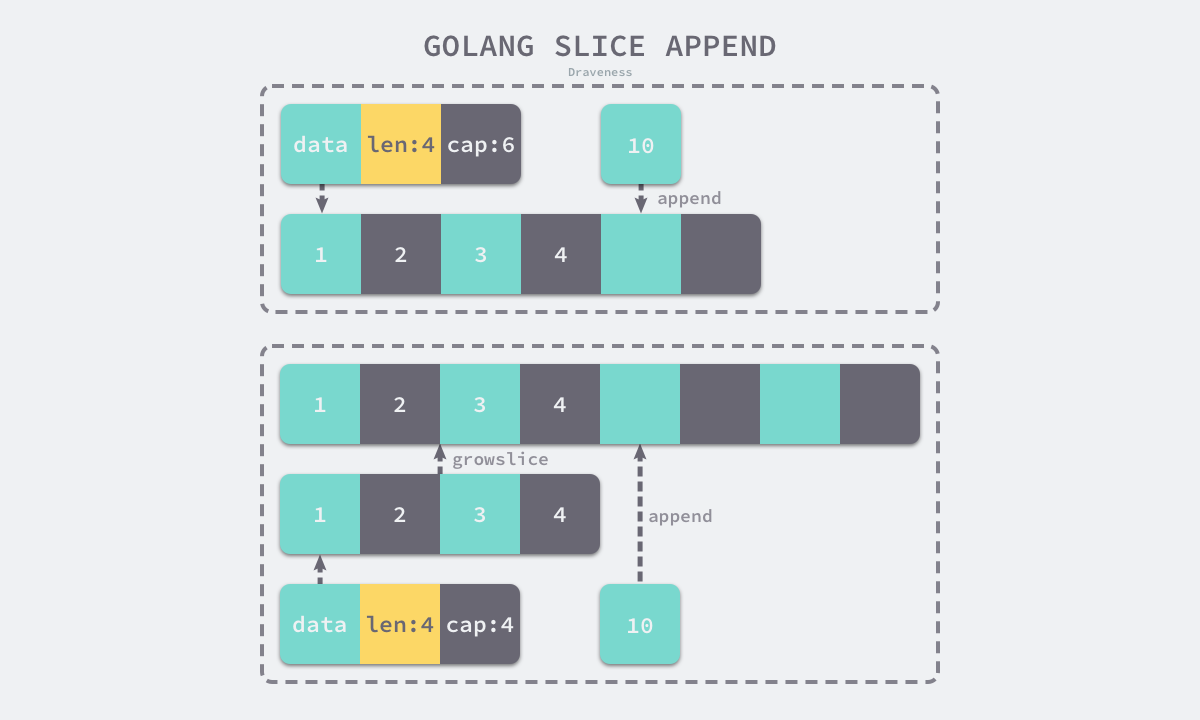
2.6.1 追加 append
追加根据是否覆盖原切片变量,有两种情况:
- 覆盖原切片变量,直接修改切片结构体的字段值
- 不覆盖原切片变量,创建新的切片结构体
2.6.2 扩容
扩容策略:
- 若期望容量大于原容量两倍,则使用期望容量
- 若长度小于 1024,则容量翻倍
- 若长度大于 1024,每次增加 25%,直到大于期望容量
go v1.18之后,策略更改为:
- 若期望容量大于原容量的两倍,使用期望容量
- 若切片长度小于 256,则翻倍
- 若切片长度大于 256,则新容量由计算公式算出:
上述策略获取的是大致容量,具体容量会跟据切片元素的大小进行内存对齐后计算出来。
内存对齐会用到runtime.class_to_size数组。
例如:
var arr []int64
arr = append(arr, 1, 2, 3, 4, 5)
容量为:
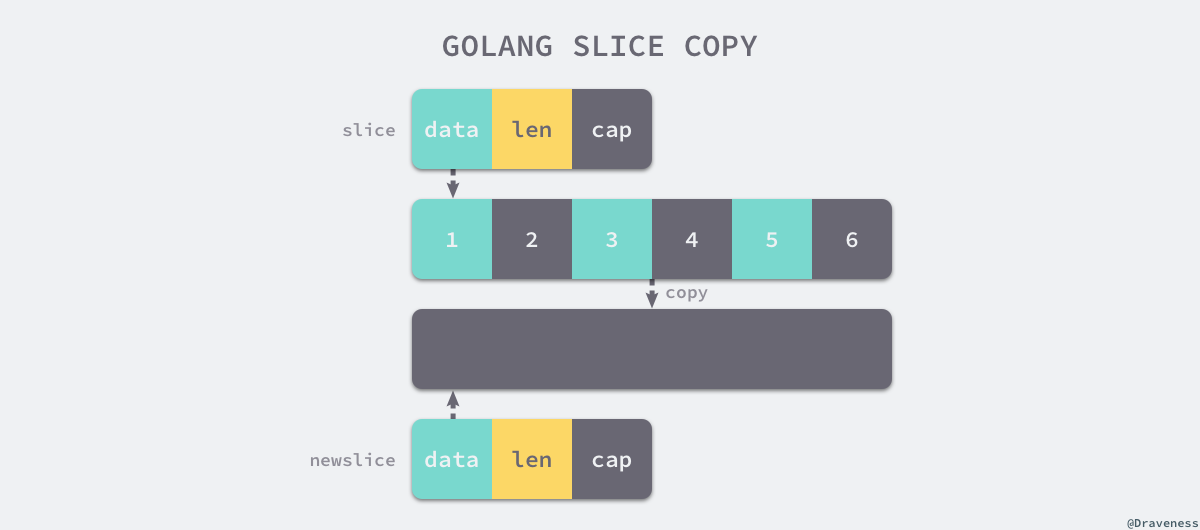
2.7 拷贝
切片的拷贝会将整块的内存的内容拷贝到目标内存中:
3. 哈希表
3.1 定义
In computing, a hash table, also known as hash map, is a data structure that implements an associative array, also called dictionary, which is an abstract data type that maps keys to values.
3.2 设计原理
哈希表的设计由两个关键:
- 哈希函数,使用Key计算出哈希值
- 哈希冲突解决,当发生哈希冲突(不同的Key的哈希值相同)时如何解决
常见的哈希冲突解决方法:
开放寻址法 数据结构:数组 核心思想:依次探测和比较数组中的元素以判断键值是否在哈希表中
- 装载因子:
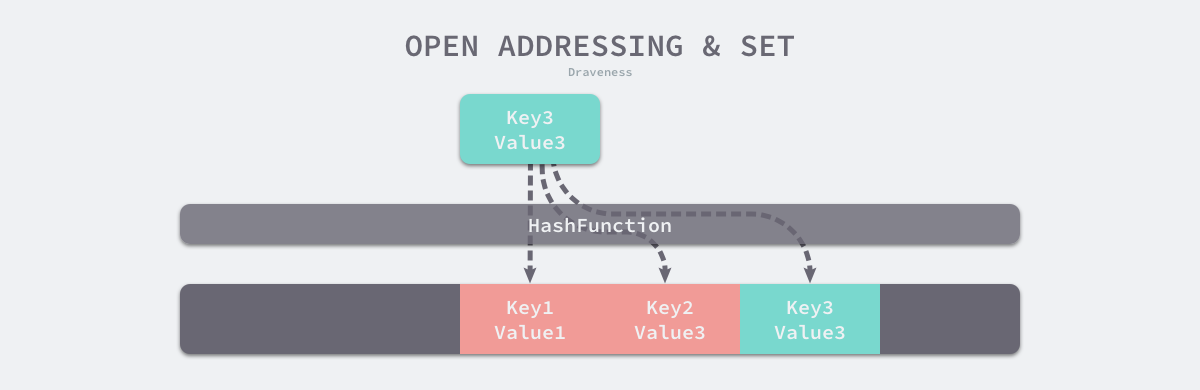
open-addressing-and-set 拉链法 数据结构:数组+链表(或红黑树) 核心思想: 通过哈希值定位桶,在桶中寻找目标元素
- 桶:数组元素,类型为链表
- 装载因子:
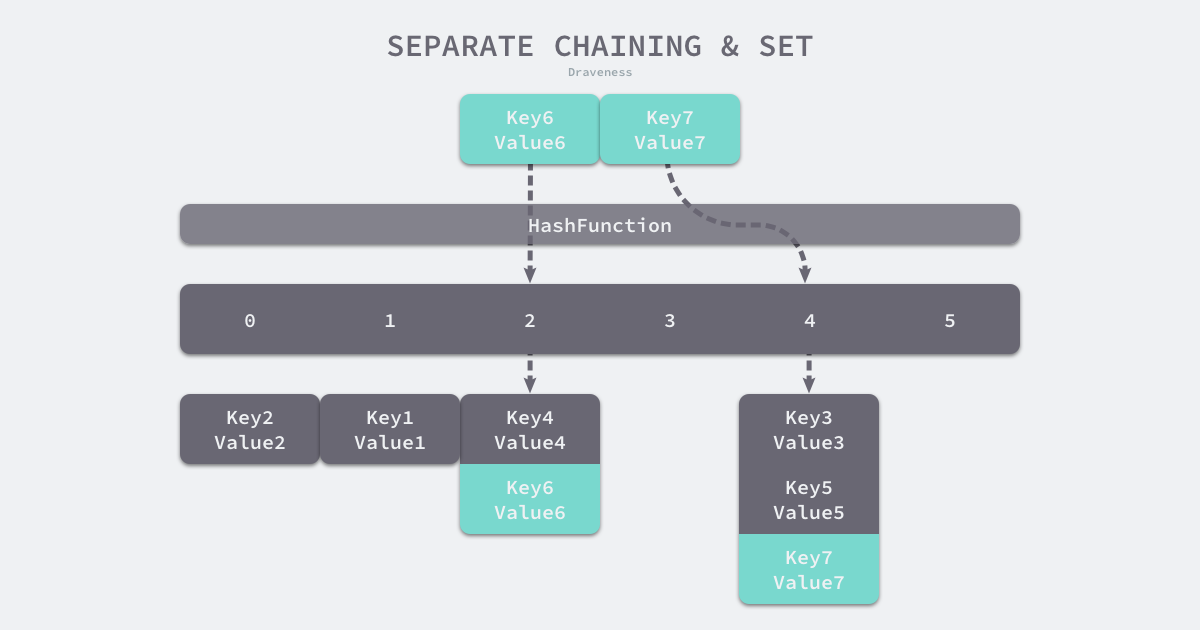
separate-chaing-and-set
3.3 数据结构
Golang 使用多种结构体表示哈希表,runtime.hmap是最核心的结构体:
type hmap struct {
count int
flags uint8
B uint8
noverflow uint16
hash0 uint32
buckets unsafe.Pointer
oldbuckets unsafe.Pointer
nevacuate uintptr
extra *mapextra
}
type mapextra struct {
overflow *[]*bmap
oldoverflow *[]*bmap
nextOverflow *bmap
}
Count:哈希表元素数量B:用于表示哈希表持有的桶的数量;满足$\text{BucketsCount} = 2^B $hash0:哈希种子,用于为哈希值计算引入随机性,创建哈希表时确定oldbuckets:哈希表扩容时用于保存原buckets
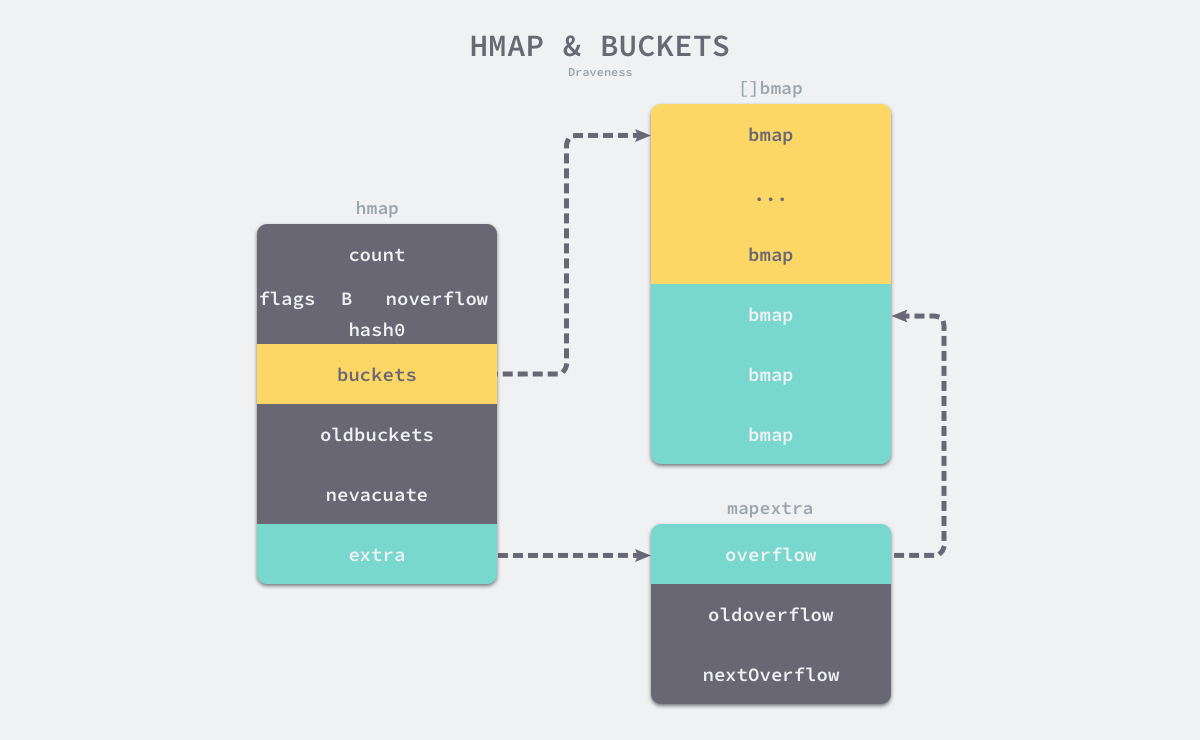
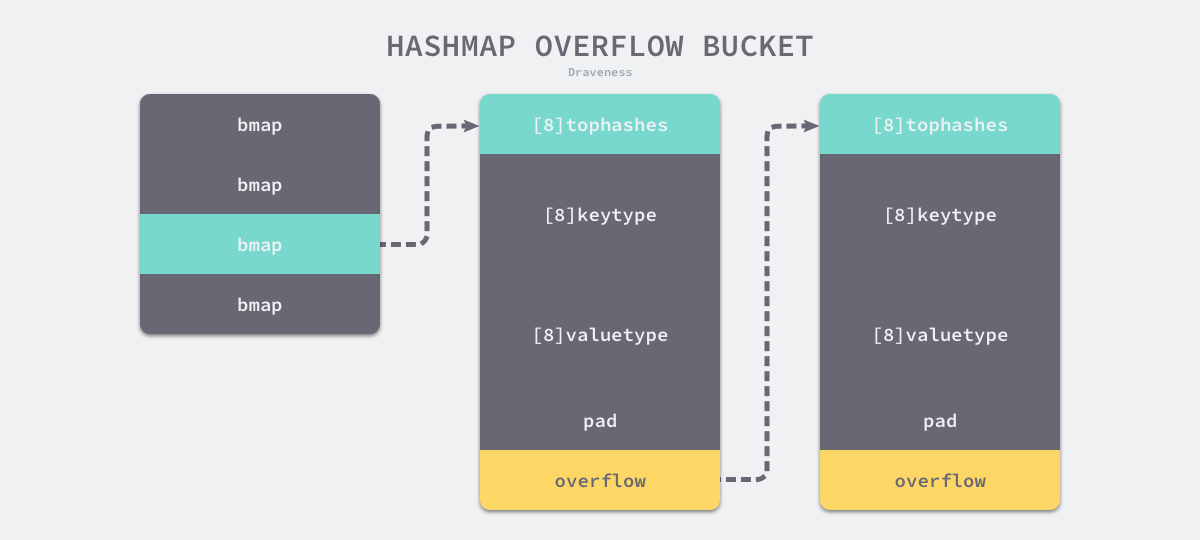
桶的结构体runtime.bmap在源码中只有一个字段
type bmap struct {
tophash [bucketCnt]uint8
}
之后会在运行时构建其他字段,相当于:
type bmap struct {
topbits [8]uint8
keys [8]keytype
values [8]valuetype
pad uintptr
overflow uintptr
}
桶中存储的主要内容为:
- 哈希值的高 8 位数组,长度 8
- Key 的数组,长度 8
- Value 的数组,长度 8
3.4 初始化
初始化有两种方式:
- 字面量
make关键字
字面量
例如:
hash := map[string]int{
"1": 2,
"3": 4,
"5": 6,
}
编译器会根据元素数量不同,选择不同的方式:
元素数量小于等于 25 个,转换成简单赋值代码:
hash := make(map[string]int, 3) hash["1"] = 2 hash["3"] = 4 hash["5"] = 6元素数量大于 25 个,创建两个数组分别存储Key和Value,通过 for 循环加入哈希表
make
使用make关键字,将会调用runtime.makemap:
func makemap(t *maptype, hint int, h *hmap) *hmap {
mem, overflow := math.MulUintptr(uintptr(hint), t.bucket.size)
if overflow || mem > maxAlloc {
hint = 0
}
if h == nil {
h = new(hmap)
}
h.hash0 = fastrand()
B := uint8(0)
for overLoadFactor(hint, B) {
B++
}
h.B = B
if h.B != 0 {
var nextOverflow *bmap
h.buckets, nextOverflow = makeBucketArray(t, h.B, nil)
if nextOverflow != nil {
h.extra = new(mapextra)
h.extra.nextOverflow = nextOverflow
}
}
return h
}
主要流程:
- 检查哈希表占用内存是否溢出或超出可分配内存大小
- 获取随机哈希种子
- 计算最小需要的桶数量
- 使用
runtime.makeBucketArray创建桶的数组
runtime.makeBucketArray用于创建桶数组,其会在内存中分配一段连续的空间用于存储数据:
func makeBucketArray(t *maptype, b uint8, dirtyalloc unsafe.Pointer) (buckets unsafe.Pointer, nextOverflow *bmap) {
base := bucketShift(b)
nbuckets := base
if b >= 4 {
nbuckets += bucketShift(b - 4)
sz := t.bucket.size * nbuckets
up := roundupsize(sz)
if up != sz {
nbuckets = up / t.bucket.size
}
}
buckets = newarray(t.bucket, int(nbuckets))
if base != nbuckets {
nextOverflow = (*bmap)(add(buckets, base*uintptr(t.bucketsize)))
last := (*bmap)(add(buckets, (nbuckets-1)*uintptr(t.bucketsize)))
last.setoverflow(t, (*bmap)(buckets))
}
return buckets, nextOverflow
}
根据桶的数量,会有不同的流程:
- 桶数量小于 ,因数据较少使用溢出桶的概率较低,不会创建溢出桶
- 桶数量大于等于 ,额外创建溢出桶,初始化时的溢出桶和桶是在同一块连续内存空间中的
3.5 读写操作
访问
读取哈希表有两种形式:
val := hash[key]val, ok := hash[key],ok用于表示键值对是否存在,bool类型
在编译期,会根据左边参数数量选择不同的操作:
- 只有一个参数,使用
runtime.mapaccess1 - 有两个参数,使用
runtime.mapaccess2
func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
alg := t.key.alg
hash := alg.hash(key, uintptr(h.hash0))
m := bucketMask(h.B)
b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.bucketsize)))
top := tophash(hash)
bucketloop:
for ; b != nil; b = b.overflow(t) {
for i := uintptr(0); i < bucketCnt; i++ {
if b.tophash[i] != top {
if b.tophash[i] == emptyRest {
break bucketloop
}
continue
}
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
if alg.equal(key, k) {
v := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize))
return v
}
}
}
return unsafe.Pointer(&zeroVal[0])
}
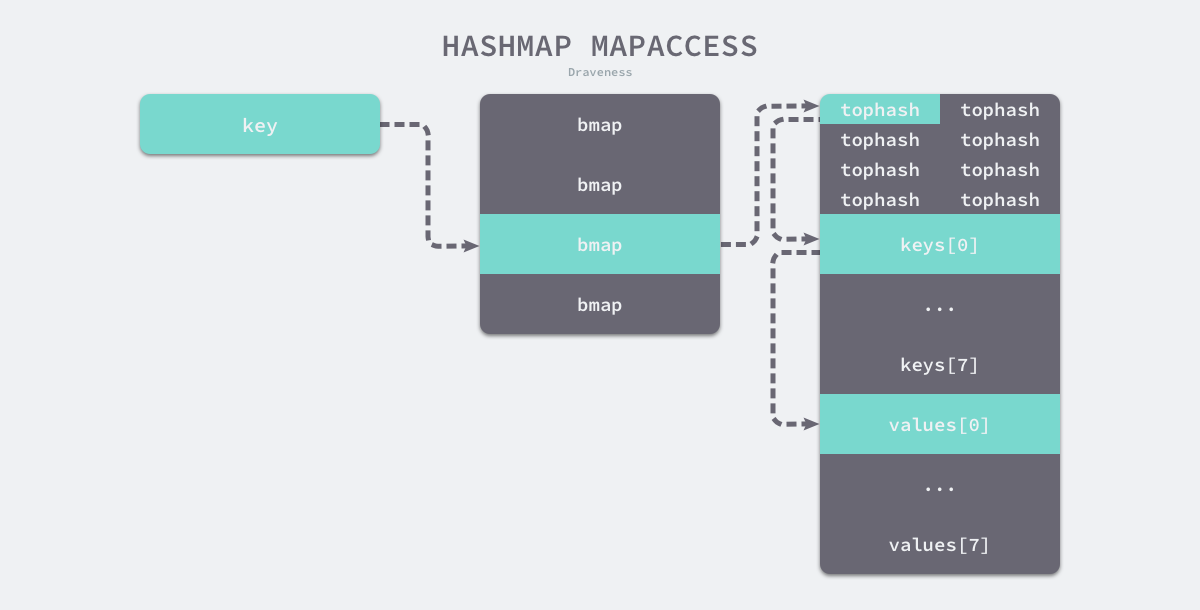
访问数据流程
通过 Key 计算哈希值
通过哈希值的取模运算获取桶的在数组中的索引位置 计算结果是哈希值的 低 B 位
遍历桶及其溢出桶
寻找哈希值的高 8 位,是否在桶的
tophash数组中:若不在,则在下一个溢出桶中寻找
若在,计算出
Key的位置,比较key是否相同:若key相同,则计算value的位置,并返回
若key不同,继续比较
tophash,继续步骤 3)
写入
hash[key] = value表示写入操作。
在编译期间会转换成runtime.mapassign函数的调用:
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
alg := t.key.alg
hash := alg.hash(key, uintptr(h.hash0))
h.flags ^= hashWriting
again:
bucket := hash & bucketMask(h.B)
b := (*bmap)(unsafe.Pointer(uintptr(h.buckets) + bucket*uintptr(t.bucketsize)))
top := tophash(hash)
首先根据传入的Key:
计算哈希值
定位桶位置
获取哈希值高 8 位
var inserti *uint8
var insertk unsafe.Pointer
var val unsafe.Pointer
bucketloop:
for {
for i := uintptr(0); i < bucketCnt; i++ {
if b.tophash[i] != top {
if isEmpty(b.tophash[i]) && inserti == nil {
inserti = &b.tophash[i]
insertk = add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
val = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize))
}
if b.tophash[i] == emptyRest {
break bucketloop
}
continue
}
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
if !alg.equal(key, k) {
continue
}
val = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize))
goto done
}
ovf := b.overflow(t)
if ovf == nil {
break
}
b = ovf
}
然后遍历桶及其溢出桶:
- 若找到相同的Key,返回对应的 Value 的地址
- 若未找到,则插入
tophash[i]为空的位置,并返回对应的Key,Value地址
if inserti == nil {
newb := h.newoverflow(t, b)
inserti = &newb.tophash[0]
insertk = add(unsafe.Pointer(newb), dataOffset)
val = add(insertk, bucketCnt*uintptr(t.keysize))
}
typedmemmove(t.key, insertk, key)
*inserti = top
h.count++
done:
return val
}
若桶以及溢出桶都已经满了,则:
- 创建新的溢出桶,链接至当前已有桶的末尾
- 增加
noverflow计数 - 返回新元素在新建溢出桶的插入位置
runtime.mapassign函数并不会进行赋值操作,只会返回相应位置的地址,真正的赋值/写入操作在编译期间插入:
00018 (+5) CALL runtime.mapassign_fast64(SB)
00020 (5) MOVQ 24(SP), DI ;; DI = &value
00026 (5) LEAQ go.string."88"(SB), AX ;; AX = &"88"
00027 (5) MOVQ AX, (DI) ;; *DI = AX
写入数据流程
- 根据 Key 计算哈希值
- 根据哈希值进行取模运算,得出桶在数组中的索引位置,结果是哈希值的 低 B 位
- 遍历桶及其溢出桶,比较哈希值的高 8 位和桶中的
tophash数组的元素:- 若
tophash不同,则判断tophash[i]是否为空- 若为空则表示当前位置为插入位置,计算Key和Value的地址后返回
- 不为空,则继续比较下一个
tophash,继续步骤 3)
- 若
tophash相同,则判断Key是否相同:- 若Key相同,则计算并返回Key和Value的地址
- 若Key不同,则继续比较下一个
tophash, 继续步骤 3)
- 若
- 若仍未找到插入位置,则表示桶及其溢出桶已满,创建新的溢出桶,链接至当前桶的末尾,写入哈希值的高 8 位,并返回Key和Value插入位置的地址。
扩容
当触发特定条件时,哈希表会进行扩容。
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
...
if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {
hashGrow(t, h)
goto again
}
...
}
runtime.mapassign函数会在两种情况下触发扩容,并且扩容策略也不同:
- 装载因子大于 6.5,触发翻倍扩容
- 溢出桶的数量过多,触发等量扩容
扩容的入口函数,runtime.hashGrow:
func hashGrow(t *maptype, h *hmap) {
bigger := uint8(1)
if !overLoadFactor(h.count+1, h.B) {
bigger = 0
h.flags |= sameSizeGrow
}
oldbuckets := h.buckets
newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil)
h.B += bigger
h.flags = flags
h.oldbuckets = oldbuckets
h.buckets = newbuckets
h.nevacuate = 0
h.noverflow = 0
h.extra.oldoverflow = h.extra.overflow
h.extra.overflow = nil
h.extra.nextOverflow = nextOverflow
}
扩容过程中会通过runtime.makeBucketArray创建新桶数组,并将原桶数组设置到oldbuckets上,新桶设置到buckets上;对于溢出桶采用同样的逻辑处理。

runtime.hashGrow函数只是根据扩容的类型创建了相应数量的新桶,并未进行数据的迁移。数据的迁移工作交给runtime.evacuate完成:
func evacuate(t *maptype, h *hmap, oldbucket uintptr) {
b := (*bmap)(add(h.oldbuckets, oldbucket*uintptr(t.bucketsize)))
newbit := h.noldbuckets()
if !evacuated(b) {
var xy [2]evacDst
x := &xy[0]
x.b = (*bmap)(add(h.buckets, oldbucket*uintptr(t.bucketsize)))
x.k = add(unsafe.Pointer(x.b), dataOffset)
x.v = add(x.k, bucketCnt*uintptr(t.keysize))
y := &xy[1]
y.b = (*bmap)(add(h.buckets, (oldbucket+newbit)*uintptr(t.bucketsize)))
y.k = add(unsafe.Pointer(y.b), dataOffset)
y.v = add(y.k, bucketCnt*uintptr(t.keysize))
runtime.evacuate会将一个旧桶中的数据分流到两个新桶中,会创建两个runtime.evacDst结构体保存分配上下文,其分别指向不同的新桶: 
等量扩容
若为等量扩容,两个runtime.evacDst结构体只会被初始化一个,新旧桶的是一对一的
翻倍扩容
若为翻倍扩容,旧桶数据会被分流到两个不同的新桶,流程如下:
- 新桶1的位置和原桶位置索引相同,即
hash & bucketMusk - 新桶2的位置,将由原桶掩码增加一位计算得出,即
hash & newBucketMusk
例如:
0xb72bfae3f3285244c4732ce457cca823bc189e0b & 0b11 --> 3 // 原桶和新桶1的位置
0xb72bfae3f3285244c4732ce457cca823bc189e0b & 0b111 --> 7 // 新桶2的位置
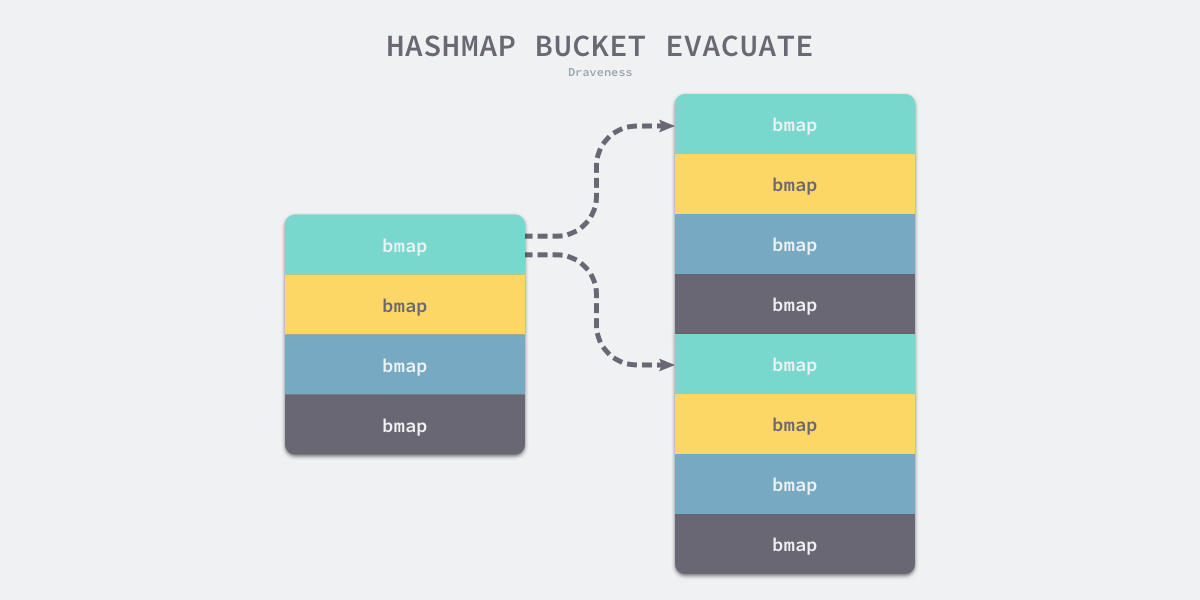
数据分流
扩容并操作不是原子的,而是在每次进行写入/删除操作时,触发runtime.growWork将当前访问的桶中的数据拷贝至新桶。
当进行访问操作时,若哈希表处于扩容期间,会在先去oldbukets中寻找数据。
删除
删除哈希表元素使用delete(hash, key),此函数无论Key是否存在不会有返回值。
编译期会将delete转换成ODELETE节点,并在runtime.mapdelete系列函数中选择一个。
删除的流程和写入类似,但当遇到扩容时,会先进性数据迁移,然后再到桶中搜寻并删除元素。
4. 字符串
4.1 定义
In computer programming, a string is traditionally a sequence of characters, either as a literal constant or as some kind of variable.
4.2 类型
string是 Golang 中的基本类型,其值是只读的无法更改。
在编译期间,字符串会被标记成SRODATA。
4.3 数据结构
字符串在运行时,采用reflect.StringHeader:
type StringHeader struct {
Data uintptr
Len int
}
Data: 指向数组的指针Len:字符串长度
4.4 初始化和解析
字符串有两种方式表示:
- 使用双引号
- 使用反引号
// 使用双引号
s1 := "abcd"
// 使用反引号
s2 := `ab
cd
e`
字符串的解析流程:
- 编译器先先使用
cmd/compile/internal/syntax.scanner将字符串转换成token流 cmd/compile/internal/syntax.scanner.stdString用于解析标准字符串:- 标准字符串使用双引号表示开头和结尾;
- 标准字符串需要使用反斜杠
\来逃逸双引号; - 标准字符串不能出现如下所示的隐式换行
\n;
cmd/compile/internal/syntax.scanner.rawString解析原始字符串
4.5 拼接
拼接字符串使用+号,编译器会将符号对应的OADD节点变成OADDSTR节点。
cmd/compile/internal/gc.addstr会根据字符串数目的不同选择不同的函数,但流程是类似的。
字符串拼接流程:
- 将传入的字符串放入切片
- 过滤空字符串,并计算拼接后的长度
- 若非空字符串数量为1或字符串不在栈上,直接返回
- 正常情况下,将字符串拷贝到新的内存空间
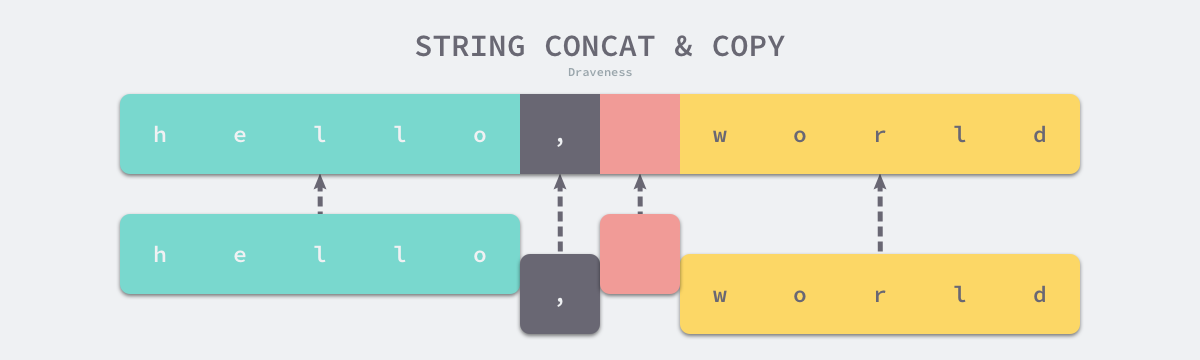
4.6 类型转换
[]byte-> string
- 计算是否需要新内存空间
- 将字符串指针换成
runtime.stringStruct指针,设置str和len - 通过
runtime.memmove将[]byte的字节复制到新的内存空间中
string -> []byte
- 若传入缓冲区,使用缓冲区存储
[]byte - 若没有,运行时会调用
runtime.rawbyteslice创建新的字节切片并拷贝字符串的字节