
3.3 哈希表
3.3.1 设计原理
哈希表的读写性能为,同时提供键值对的映射。
设计一个性能优异的哈希表,需要两个关键点:
- 哈希函数
- 解决哈希冲突
哈希函数
哈希函数的选择在很大程度上能够决定哈希表的读写性能。
理想的哈希函数,能够将不同的Key映射到不同的Val上,即一对一映射。
但因为Key的数目是远大于Val的数目的,完美的哈希函数很难实现的。
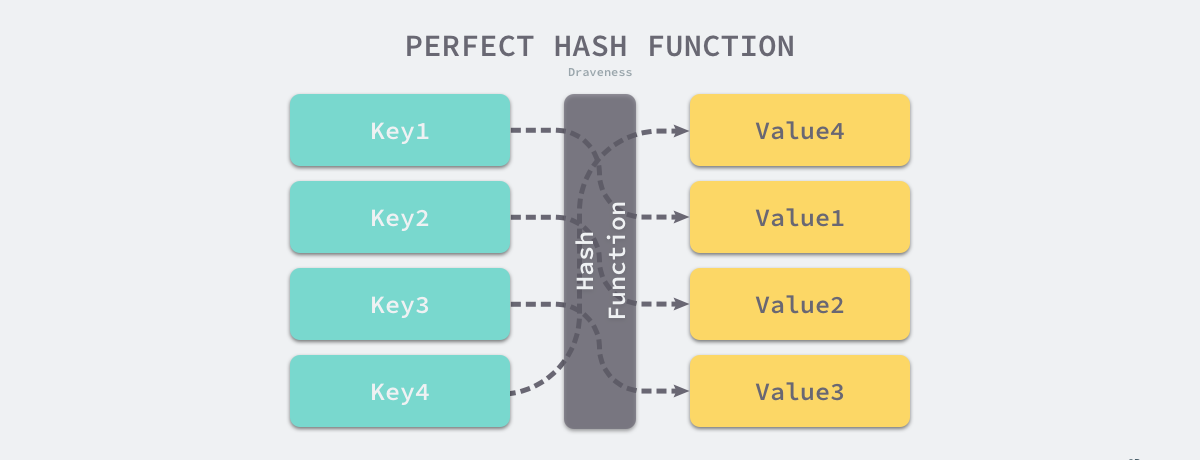
那么实际设计哈希函数,需要让结果尽可能的均匀分布,否则将带来更多哈希冲突和更差的读写性能。性能较差的哈希函数将会使得所有的操作变成。
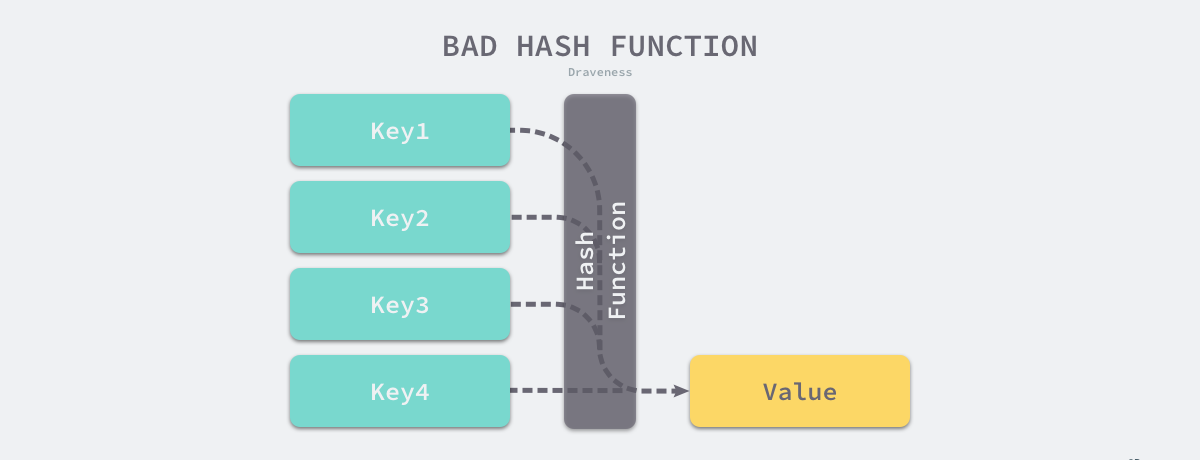
冲突解决
哈希冲突常见的解决办法有两种:
- 开放寻址法
- 拉链法
开放寻址
开放寻址法的核心思想是依次探测和比较数组中的元素以判断目标键值对是否在哈希表中。
开放寻址法的底层数据结构是数组,因为数组长度优先,故使用模运算来将数据放入数组中。例如:
index := hash(Key) % array.Lenght
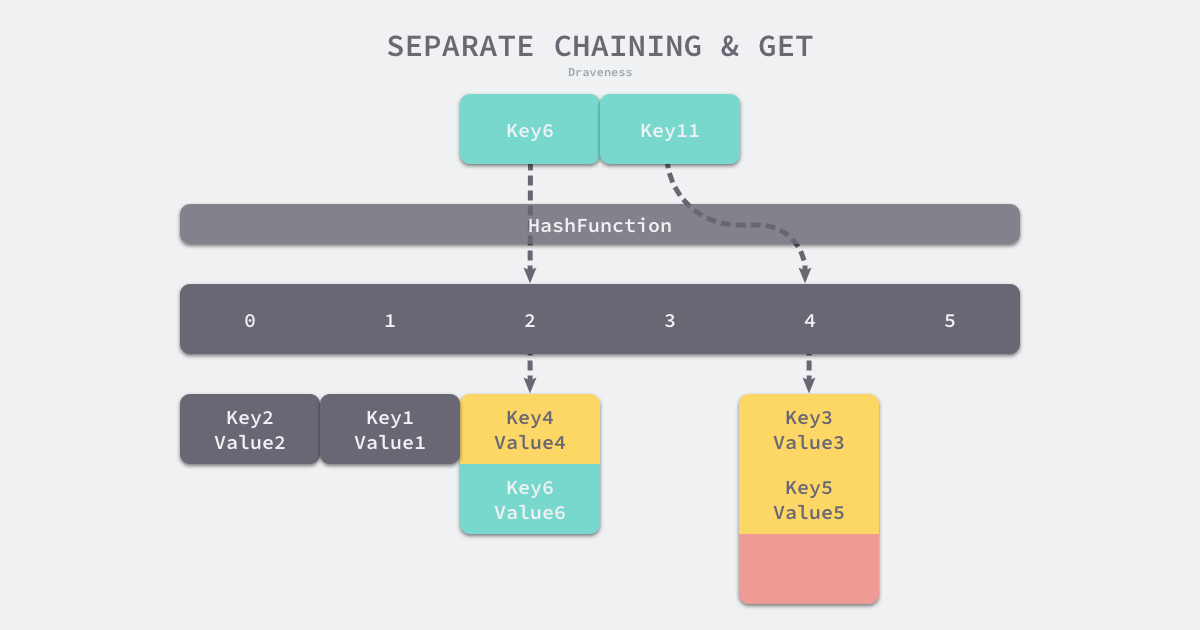
若发生哈希冲突,则写入下一个为空的位置。例如:下图中的 key1,key2处发生冲突,则写入后序的空位。
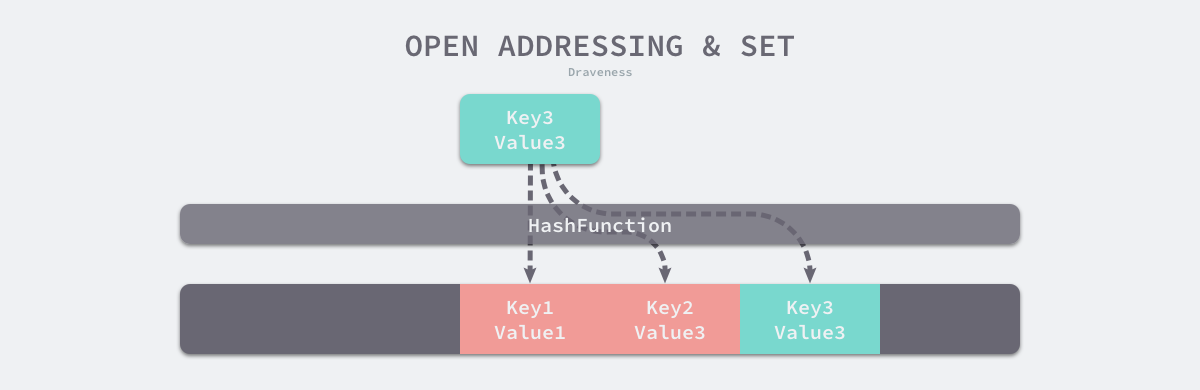
当读取key3的值时,计算的索引位置为key1 的位置,然后依次向后寻找key3查找元素直到找到或结束。
开放寻址法中对性能影响最大的是装载因子:
当装载因子达到 70% 之后,性能急剧下降;达到 100% 时将完全失效,所有操作都是O(n)。
拉链法
拉链法一般使用数组和链表(可引入红黑树以优化性能),数组的每个元素是一个链表,也被称作桶。
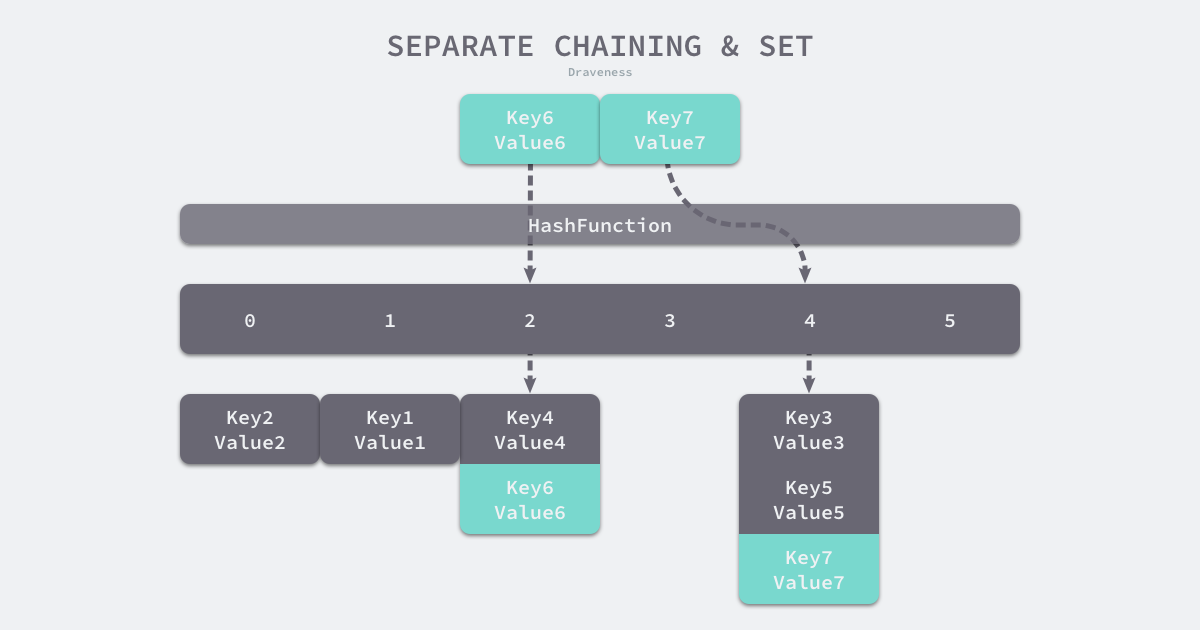
当写入数据时,先通过哈希函数计算桶的位置:
index := hash(Key) % array.Length
然后到桶中寻找键值对:
- 若找到,则更新对应
Value - 未找到,则在链表末尾追加新的元素
拉链法中的装载因子,计算方式如下:
当装载因子较大时,可以进行扩容,增加桶的数量,以防止性能下降。
3.2.2 数据结构
runtime.hmap是最核心的结构体:
// go1.17 runtime/map.go
// A header for a Go map.
type hmap struct {
count int // # live cells == size of map. Must be first (used by len() builtin)
flags uint8
B uint8 // log_2 of # of buckets (can hold up to loadFactor * 2^B items)
noverflow uint16 // approximate number of overflow buckets; see incrnoverflow for details
hash0 uint32 // hash seed
buckets unsafe.Pointer // array of 2^B Buckets. may be nil if count==0.
oldbuckets unsafe.Pointer // previous bucket array of half the size, non-nil only when growing
nevacuate uintptr // progress counter for evacuation (buckets less than this have been evacuated)
extra *mapextra // optional fields
}
// mapextra holds fields that are not present on all maps.
type mapextra struct {
overflow *[]*bmap
oldoverflow *[]*bmap
// nextOverflow holds a pointer to a free overflow bucket.
nextOverflow *bmap
}
count:哈希表元素的数量B:用于表示哈希表中的bucket数量,因为哈希表中的桶的数量为 2 的倍数,所以B存的是对数,即hash0: 哈希种子,为哈希函数的结果引入随机性,在创建哈希表时确定。调用哈希函数时使用oldbuckets: 哈希表扩容时,保存原buckets
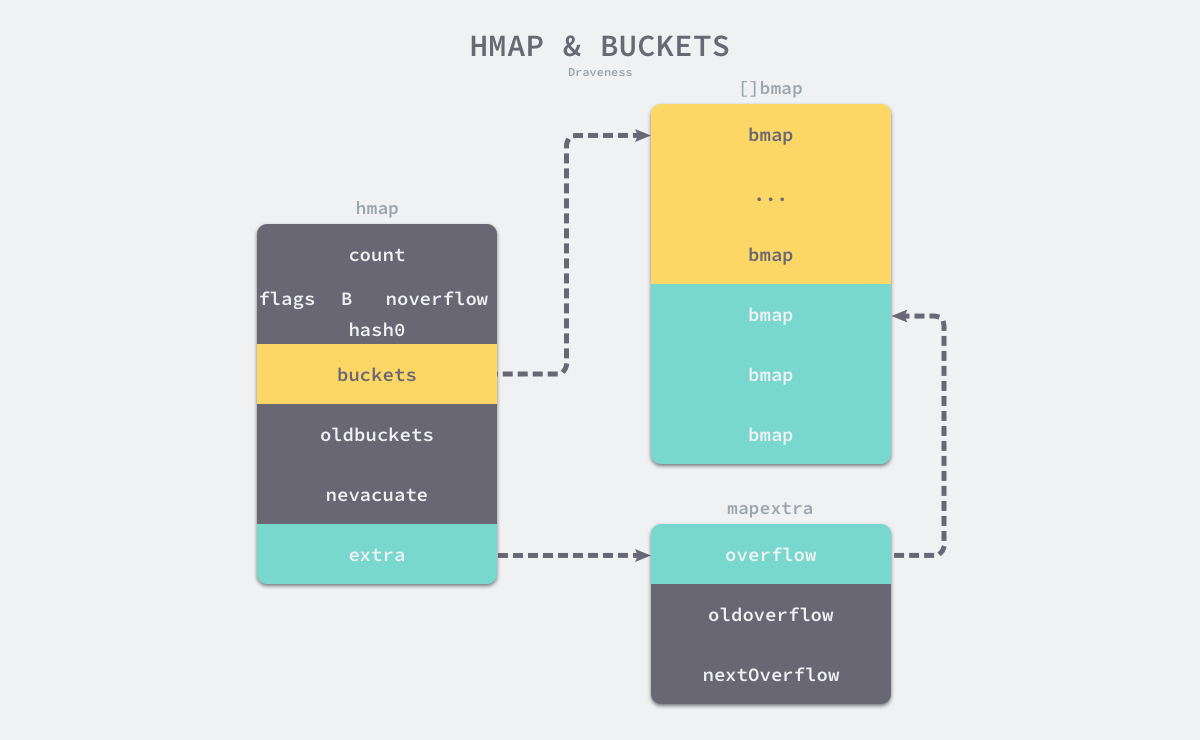
每个bmap中能够存储 8(1 << 3) 个键值对,当哈希表中的元素过多,单个桶装满时,就会使用溢出桶extra.nextOverflow来存储溢出的数据。
正常桶(黄色)和溢出桶(绿色)在内存中实际上是连续的。
hmap中的桶是runtime.bmap:
const (
// Maximum number of key/elem pairs a bucket can hold.
bucketCntBits = 3
bucketCnt = 1 << bucketCntBits
...
)
type bmap struct {
tophash [bucketCnt]uint8
}
bmap实际上只存储了哈希值的高 8 位,通过比较不同键的高 8 位可以减少访问键值对次数以提高性能。
因为哈希表可以存储不同类型的键值对,所以上述的bmap实际上是在运行时才能构建的。
根据运行时函数可以重建结构:
type bmap struct {
topbits [8]uint8
keys [8]keytype
values [8]valuetype
pad uintptr
overflow uintptr
}
3.3.3 初始化
字面量
hash := map[string]int{
"1": 2,
"3": 4,
"5": 6,
}
元素数量小于 25 个时,会转换成以下代码,将所有键值对一次性加入哈希表:
hash := make(map[string]int, 3)
hash["1"] = 2
hash["3"] = 4
hash["5"] = 6
元素数量大于 25 个时,将会创建两个数组分别存储键值,然后使用for循环加入哈希表。
hash := make(map[string]int, 26)
vstatk := []string{"1", "2", "3", ... , "26"}
vstatv := []int{1, 2, 3, ... , 26}
for i := 0; i < len(vstak); i++ {
hash[vstatk[i]] = vstatv[i]
}
运行时
若哈希表被分配到栈上,并且容量小于BUCKETSIZE = 8时,在编译阶段会快速初始化:
var h *hmap
var hv hmap
var bv bmap
h := &hv
b := &bv
h.buckets = b
h.hash0 = fashtrand0()
除此之外,使用 runtime.makemap进行初始化:
func makemap(t *maptype, hint int, h *hmap) *hmap {
mem, overflow := math.MulUintptr(uintptr(hint), t.bucket.size)
if overflow || mem > maxAlloc {
hint = 0
}
if h == nil {
h = new(hmap)
}
h.hash0 = fastrand()
B := uint8(0)
for overLoadFactor(hint, B) {
B++
}
h.B = B
if h.B != 0 {
var nextOverflow *bmap
h.buckets, nextOverflow = makeBucketArray(t, h.B, nil)
if nextOverflow != nil {
h.extra = new(mapextra)
h.extra.nextOverflow = nextOverflow
}
}
return h
}
- 计算哈希表内存是否会溢出或超过最大可分配容量
- 调用
runtime.fastrand获取一个随机的哈希种子 - 根据传入的
hint计算出需要的最小需要的桶的数量 - 使用
runtime.makeBucketArray创建用于保存桶的数组
runtime.makeBucketArray 会根据传入的 B 计算出的需要创建的桶数量并在内存中分配一片连续的空间用于存储数据:
func makeBucketArray(t *maptype, b uint8, dirtyalloc unsafe.Pointer) (buckets unsafe.Pointer, nextOverflow *bmap) {
base := bucketShift(b)
nbuckets := base
if b >= 4 {
nbuckets += bucketShift(b - 4)
sz := t.bucket.size * nbuckets
up := roundupsize(sz)
if up != sz {
nbuckets = up / t.bucket.size
}
}
buckets = newarray(t.bucket, int(nbuckets))
if base != nbuckets {
nextOverflow = (*bmap)(add(buckets, base*uintptr(t.bucketsize)))
last := (*bmap)(add(buckets, (nbuckets-1)*uintptr(t.bucketsize)))
last.setoverflow(t, (*bmap)(buckets))
}
return buckets, nextOverflow
}
- 桶的数目小于 ,数据较少,使用溢出桶的概率低,省略创建过程以减小开销
- 桶的数目大于 ,额外创建 个溢出桶
可以看出正常桶和溢出桶在内存中是连续的。
3.3.4 读写操作
使用hashmap[key]可以对哈希表进行增删改查操作:
val, ok := hash[key] // 查询
hash[key] = val // 增加 或 修改
delete(hash, key) // 删除
访问
在编译的类型检查期间,hash[key] 以及类似的操作都会被转换成哈希的 OINDEXMAP 操作,中间代码生成阶段会在 cmd/compile/internal/gc.walkexpr 函数中将这些 OINDEXMAP 操作转换成如下的代码:
v := hash[key] // => v := *mapaccess1(maptype, hash, &key)
v, ok := hash[key] // => v, ok := mapaccess2(maptype, hash, &key)
赋值语句左侧接受参数的个数会决定使用的运行时方法:
- 当接受一个参数时,会使用
runtime.mapaccess1,该函数仅会返回一个指向目标值的指针; - 当接受两个参数时,会使用
runtime.mapaccess2,除了返回目标值之外,它还会返回一个用于表示当前键对应的值是否存在的bool值
runtime.mapaccess1 会先通过哈希表设置的哈希函数、种子获取当前键对应的哈希,再通过 runtime.bucketMask 和 runtime.add 拿到该键值对所在的桶序号和哈希高位的 8 位数字。
func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
alg := t.key.alg
hash := alg.hash(key, uintptr(h.hash0))
m := bucketMask(h.B)
b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.bucketsize)))
top := tophash(hash)
bucketloop:
for ; b != nil; b = b.overflow(t) {
for i := uintptr(0); i < bucketCnt; i++ {
if b.tophash[i] != top {
if b.tophash[i] == emptyRest {
break bucketloop
}
continue
}
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
if alg.equal(key, k) {
v := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize))
return v
}
}
}
return unsafe.Pointer(&zeroVal[0])
}
在 bucketloop 循环中,哈希会依次遍历正常桶和溢出桶中的数据:
先比较哈希的高 8 位和桶中存储的
tophash,后比较传入的和桶中的值以加速数据的读写。
用于选择桶序号的是哈希的最低几位,而用于加速访问的是哈希的高 8 位,这种设计能够减少同一个桶中有大量相等 tophash 的概率影响性能。
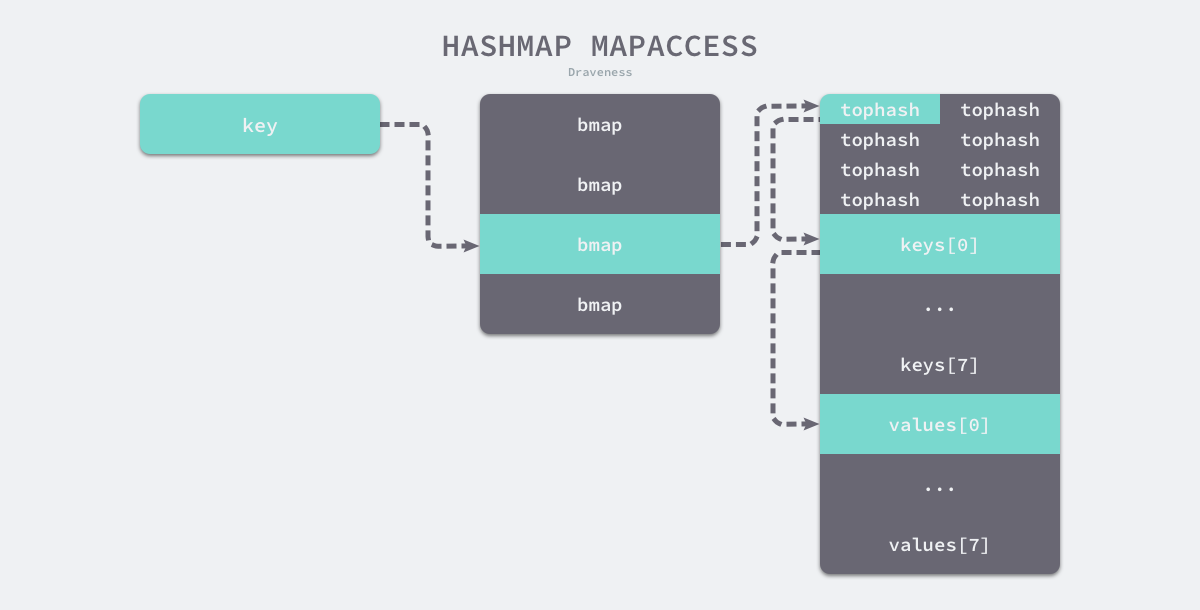
如上图所示,每一个桶都是一整片的内存空间,当发现桶中的 tophash 与传入键的 tophash 匹配之后,会通过指针和偏移量获取哈希中存储的键 keys[0] 并与 key 比较,如果两者相同就会获取目标值的指针 values[0] 并返回。
runtime.mapaccess2 只是在mapaccess1 的基础上多返回了一个标识键值对是否存在的bool值。
写入
当表达式hash[key]出现在赋值符左侧时,表达式将在编译期被转换成runtime.mapassign。
首先获取计算哈希值,获取其对应的桶:
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
alg := t.key.alg
hash := alg.hash(key, uintptr(h.hash0))
h.flags ^= hashWriting
again:
bucket := hash & bucketMask(h.B)
b := (*bmap)(unsafe.Pointer(uintptr(h.buckets) + bucket*uintptr(t.bucketsize)))
top := tophash(hash)
通过遍历桶和溢出桶,比较tohash和key,找到就返回目标位置的地址。
inserti: 插入的tophash的地址insertk: 插入的 Key 的地址val: 插入的 value 的地址
var inserti *uint8
var insertk unsafe.Pointer
var val unsafe.Pointer
bucketloop:
for {
for i := uintptr(0); i < bucketCnt; i++ {
if b.tophash[i] != top {
if isEmpty(b.tophash[i]) && inserti == nil {
inserti = &b.tophash[i]
insertk = add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
val = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize))
}
if b.tophash[i] == emptyRest {
break bucketloop
}
continue
}
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
if !alg.equal(key, k) {
continue
}
val = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize))
goto done
}
ovf := b.overflow(t)
if ovf == nil {
break
}
b = ovf
}
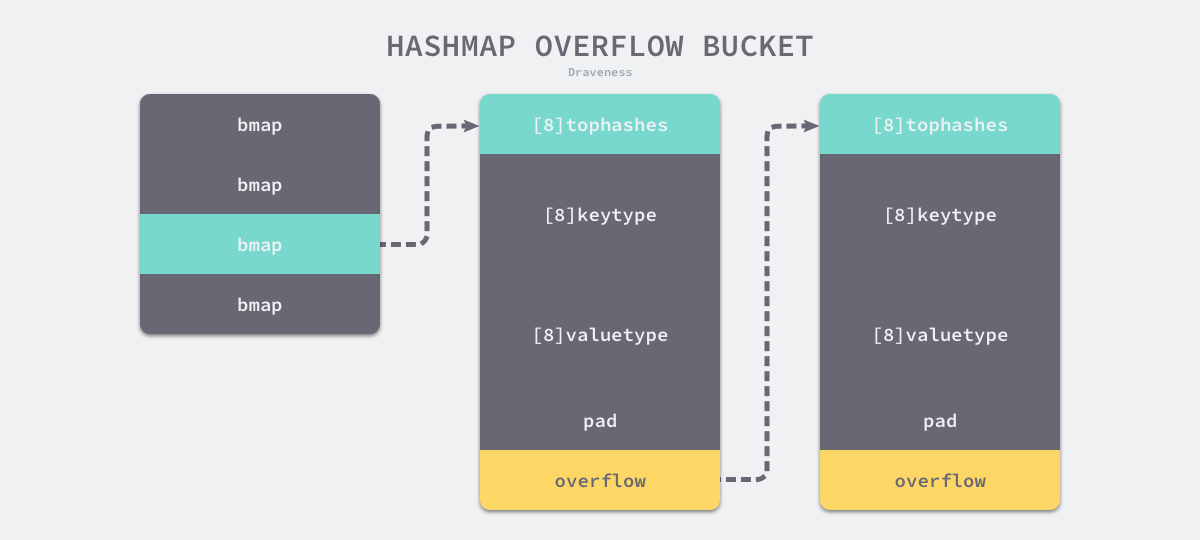
若当前桶已满,则会使用runtime.hmap.newoverflow创建新桶并或者预创建的溢出桶来存储数据;新创建的桶会被追加到已有桶的末尾,并增加哈希表的noverflow计数器。
if inserti == nil {
newb := h.newoverflow(t, b)
inserti = &newb.tophash[0]
insertk = add(unsafe.Pointer(newb), dataOffset)
val = add(insertk, bucketCnt*uintptr(t.keysize))
}
typedmemmove(t.key, insertk, key)
*inserti = top
h.count++
done:
return val
}
若键值对不存在,则为新的键值对规划存储的内存地址,runtime.typedmemmove 将key移动到对应的内存空间,并返回Value对应的地址。
若键值对存在,则直接返回目标区域的地址。
runtime.mapassign并不会进行赋值操作,只会返回内存地址,赋值操作会在编译期插入:
00018 (+5) CALL runtime.mapassign_fast64(SB)
00020 (5) MOVQ 24(SP), DI ;; DI = &value
00026 (5) LEAQ go.string."88"(SB), AX ;; AX = &"88"
00027 (5) MOVQ AX, (DI) ;; *DI = AX
扩容
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
...
if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {
hashGrow(t, h)
goto again
}
...
}
runtime.mapassign 函数会在两种情况发生时触发哈希的扩容:
- 装载因子大于 6.5
- 溢出桶数量过多
因为 Golang 的哈希表扩容不是原子过程,所以还需要判断当前是否处于扩容阶段,避免二次扩容。
扩容方式根据触发条件不同分为两种:
- 溢出桶过多,则进行等量扩容
- 装载因子过大,则进行翻倍扩容
等量扩容 和 翻倍扩容
当持续向哈希表中插入数据,删除数据时,若哈希表的数据量没有超过阈值,就会不断积累溢出桶导致内存泄漏。
等量扩容创建新桶保存数据,并让垃圾回收清理旧的溢出桶并释放内存。
扩容入口runtime.hashGrow:
func hashGrow(t *maptype, h *hmap) {
bigger := uint8(1)
if !overLoadFactor(h.count+1, h.B) {
bigger = 0
h.flags |= sameSizeGrow
}
oldbuckets := h.buckets
newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil)
h.B += bigger
h.flags = flags
h.oldbuckets = oldbuckets
h.buckets = newbuckets
h.nevacuate = 0
h.noverflow = 0
h.extra.oldoverflow = h.extra.overflow
h.extra.overflow = nil
h.extra.nextOverflow = nextOverflow
}
扩容过程中会使用runtime.makeBucketArray 创建一组新桶和预创建的溢出桶,然后将原有桶数组设置到oldbuckets上,新桶数组放到buckets上;溢出桶也是如此。

hashGrow只是完成新桶的创建,而数据的迁移使用runtime.evacuate ,其会对传入桶中的数据进行再分配。
func evacuate(t *maptype, h *hmap, oldbucket uintptr) {
b := (*bmap)(add(h.oldbuckets, oldbucket*uintptr(t.bucketsize)))
newbit := h.noldbuckets()
if !evacuated(b) {
var xy [2]evacDst
x := &xy[0]
x.b = (*bmap)(add(h.buckets, oldbucket*uintptr(t.bucketsize)))
x.k = add(unsafe.Pointer(x.b), dataOffset)
x.v = add(x.k, bucketCnt*uintptr(t.keysize))
y := &xy[1]
y.b = (*bmap)(add(h.buckets, (oldbucket+newbit)*uintptr(t.bucketsize)))
y.k = add(unsafe.Pointer(y.b), dataOffset)
y.v = add(y.k, bucketCnt*uintptr(t.keysize))
runtime.evacuate 会将一个旧桶中的数据分流到两个新桶,所以创建了两个用于保存分配上下文的结构体runtime.evacDst 分别指向一个新桶:

若是等量扩容,新桶和旧桶是一对一的关系,此时只会初始化一个runtime.evacDst 。
若是翻倍扩容,每个旧桶元素都将分流至两个新桶中。
for ; b != nil; b = b.overflow(t) {
k := add(unsafe.Pointer(b), dataOffset)
v := add(k, bucketCnt*uintptr(t.keysize))
for i := 0; i < bucketCnt; i, k, v = i+1, add(k, uintptr(t.keysize)), add(v, uintptr(t.valuesize)) {
top := b.tophash[i]
k2 := k
var useY uint8
hash := t.key.alg.hash(k2, uintptr(h.hash0))
if hash&newbit != 0 {
useY = 1
}
b.tophash[i] = evacuatedX + useY
dst := &xy[useY]
if dst.i == bucketCnt {
dst.b = h.newoverflow(t, dst.b)
dst.i = 0
dst.k = add(unsafe.Pointer(dst.b), dataOffset)
dst.v = add(dst.k, bucketCnt*uintptr(t.keysize))
}
dst.b.tophash[dst.i&(bucketCnt-1)] = top
typedmemmove(t.key, dst.k, k)
typedmemmove(t.elem, dst.v, v)
dst.i++
dst.k = add(dst.k, uintptr(t.keysize))
dst.v = add(dst.v, uintptr(t.valuesize))
}
}
...
}
哈希值通过取模运算来获取桶的编号:
$index = hash \bmod 2^B $
使用二进制运算:
即index为hash值的低 B 位。
例如:b72bfae3f3285244c4732ce457cca823bc189e0b ,桶数目为 4,则哈希值对应的索引为 3
b72bfae3f3285244c4732ce457cca823bc189e0b & 0b11 = 3
若新的哈希表有 8 个桶,在大多数情况下,原来经过桶掩码 0b11 结果为 3 的数据会因为桶掩码增加了一位变成 0b111 而分流到新的 3 号和 7 号桶,所有数据也都会被 runtime.typedmemmove 拷贝到目标桶中: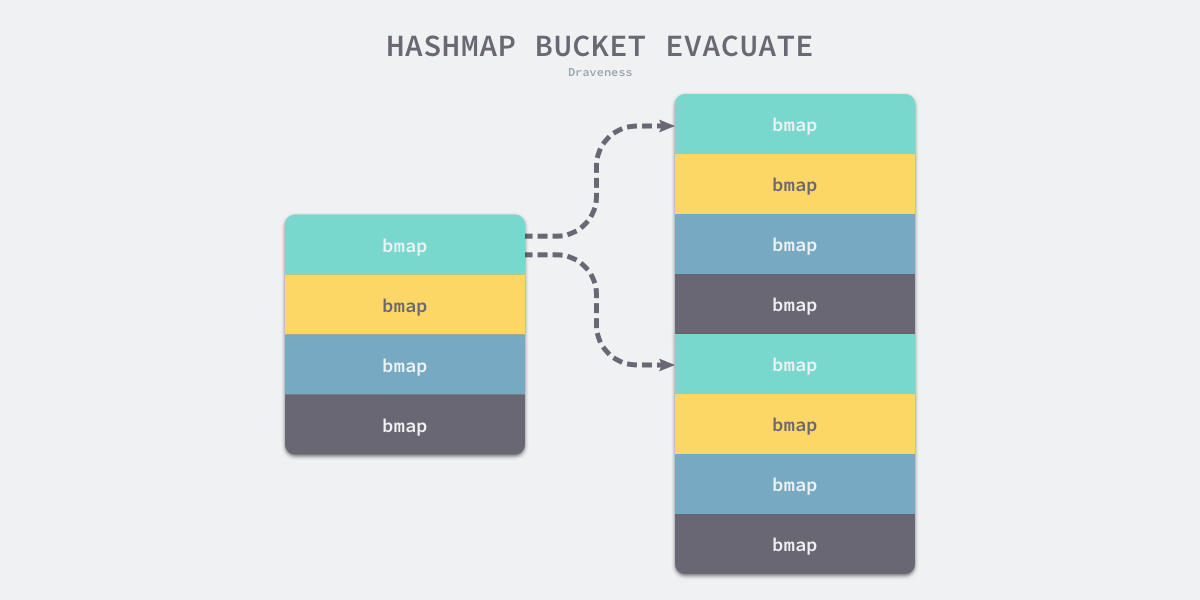
runtime.evacuate 最后会调用 runtime.advanceEvacuationMark 增加哈希的 nevacuate 计数器并在所有的旧桶都被分流后清空哈希的 oldbuckets 和 oldoverflow:
func advanceEvacuationMark(h *hmap, t *maptype, newbit uintptr) {
h.nevacuate++
stop := h.nevacuate + 1024
if stop > newbit {
stop = newbit
}
for h.nevacuate != stop && bucketEvacuated(t, h, h.nevacuate) {
h.nevacuate++
}
if h.nevacuate == newbit { // newbit == # of oldbuckets
h.oldbuckets = nil
if h.extra != nil {
h.extra.oldoverflow = nil
}
h.flags &^= sameSizeGrow
}
}
数据分流
当访问元素时,若oldbuckets 存在,runtime.mapaccess1会先到旧桶中获取数据。
func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
...
alg := t.key.alg
hash := alg.hash(key, uintptr(h.hash0))
m := bucketMask(h.B)
b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.bucketsize)))
if c := h.oldbuckets; c != nil {
if !h.sameSizeGrow() {
m >>= 1
}
oldb := (*bmap)(add(c, (hash&m)*uintptr(t.bucketsize)))
if !evacuated(oldb) {
b = oldb
}
}
bucketloop:
...
}
当进行处于扩容状态时,每次进行写入操作都会触发runtime.growWork 增量拷贝哈希表中的内容:
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
...
again:
bucket := hash & bucketMask(h.B)
if h.growing() {
growWork(t, h, bucket)
}
...
}
删除操作也会在哈希表扩容期间触发 runtime.growWork,也是计算当前值所在的桶,然后拷贝桶中的元素。
删除
delete 关键字的唯一作用就是将某一个键对应的元素从哈希表中删除,无论是该键对应的值是否存在,函数不会返回任何的结果。

在编译期间,delete 关键字会被转换成操作为 ODELETE 的节点,而 cmd/compile/internal/gc.walkexpr 会将 ODELETE 节点转换成 runtime.mapdelete 函数簇中的一个,包括 runtime.mapdelete、mapdelete_faststr、mapdelete_fast32 和 mapdelete_fast64:
func walkexpr(n *Node, init *Nodes) *Node {
switch n.Op {
case ODELETE:
init.AppendNodes(&n.Ninit)
map_ := n.List.First()
key := n.List.Second()
map_ = walkexpr(map_, init)
key = walkexpr(key, init)
t := map_.Type
fast := mapfast(t)
if fast == mapslow {
key = nod(OADDR, key, nil)
}
n = mkcall1(mapfndel(mapdelete[fast], t), nil, init, typename(t), map_, key)
}
}
runtime.mapdelete 如果在删除期间遇到了哈希表的扩容,就会分流桶中的元素,分流结束之后会找到桶中的目标元素完成键值对的删除工作。
func mapdelete(t *maptype, h *hmap, key unsafe.Pointer) {
...
if h.growing() {
growWork(t, h, bucket)
}
...
search:
for ; b != nil; b = b.overflow(t) {
for i := uintptr(0); i < bucketCnt; i++ {
if b.tophash[i] != top {
if b.tophash[i] == emptyRest {
break search
}
continue
}
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
k2 := k
if !alg.equal(key, k2) {
continue
}
*(*unsafe.Pointer)(k) = nil
v := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize))
*(*unsafe.Pointer)(v) = nil
b.tophash[i] = emptyOne
...
}
}
}
删除操作实际上是将key, value 的指针置空。
3.3.5 小结
Golang 使用拉链法来解决哈希冲突。
哈希表的桶中主要存储 哈希值高8位的数组,Key数组,Value数组(长度均为8)以及指向溢出桶的链接。
在比较Key之前会先比较tophash以加速遍历。
若桶中的元素已满,则会创建溢出桶并链接至桶的尾部(链表)。
当装载因子或溢出桶数量过大时,会触发扩容。
扩容操作只会在写入和删除时增量进行,不会导致性能的巨大抖动。