
第五章笔记总结
1. for and range
1.1 for
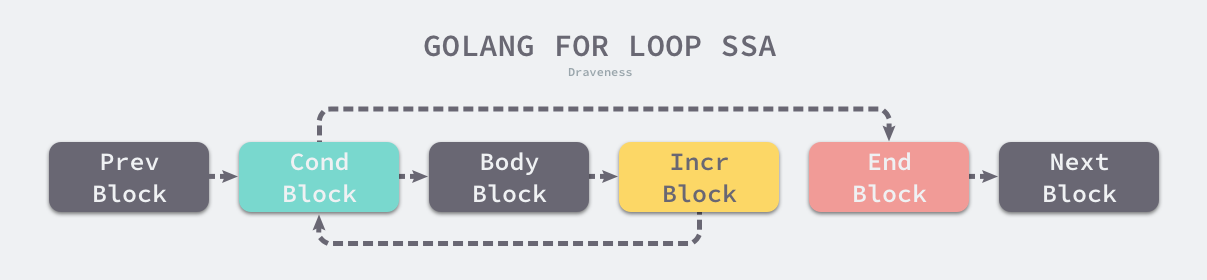
for 循环被编译器视作OFOR节点,由四个部分组成:
Ninit:循环初始化Left:循环执行条件Right:循环体结束执行语句NBody:循环体
for Ninit; Left; Right {
NBody
}
1.2 for-range
编译期会将for-range的ORANGE节点换成OFOR也就是普通for。

数组和切片
使用for-range遍历数组和切片,会拷贝原始切片,若在循环中修改切片的长度,不会改变循环次数。
遍历数组和切片有四种情况:
- 遍历数组和切片清空元素
- 使用
for range a {}遍历数组和切片 - 使用
for i := range a {}遍历数组和切片 - 使用
for i, elem := range a {}遍历数组和切片
遍历并清空数组和切片
// 原代码
for i := range a {
a[i] = zero
}
// 优化后
if len(a) != 0 {
hp = &a[0]
hn = len(a)*sizeof(elem(a))
memclrNoHeapPointers(hp, hn)
i = len(a) - 1
}
代码会被优化成使用runtime.memclrNoHeapPointers或runtime.memclrHasPointers直接清除内存区域的数据。
for range a {}
// 原代码
for range a {
...
}
// 优化之后
ha := a
hv1 := 0
hn := len(ha)
v1 := hv1
for ; hv1 < hn; hv1++ {
...
}
遍历时,拷贝原始切片的变量,遍历次数是新变量的长度。
for i := range a {}
// 原代码
for i := range a {
...
}
// 优化之后
ha := a
hv1 := 0
hn := len(ha)
v1 := hv1
for ; hv1 < hn; hv1++ {
v1 = hv1
...
}
for i, elem := range a {}
// 原代码
for i, elem := range a {
...
}
// 优化之后
ha := a
hv1 := 0
hn := len(ha)
v1 := hv1
v2 := nil
for ; hv1 < hn; hv1++ {
tmp := ha[hv1]
v1, v2 = hv1, tmp
...
}
遍历时的elem变量的地址不变,每次循环都会重新赋值。
哈希表
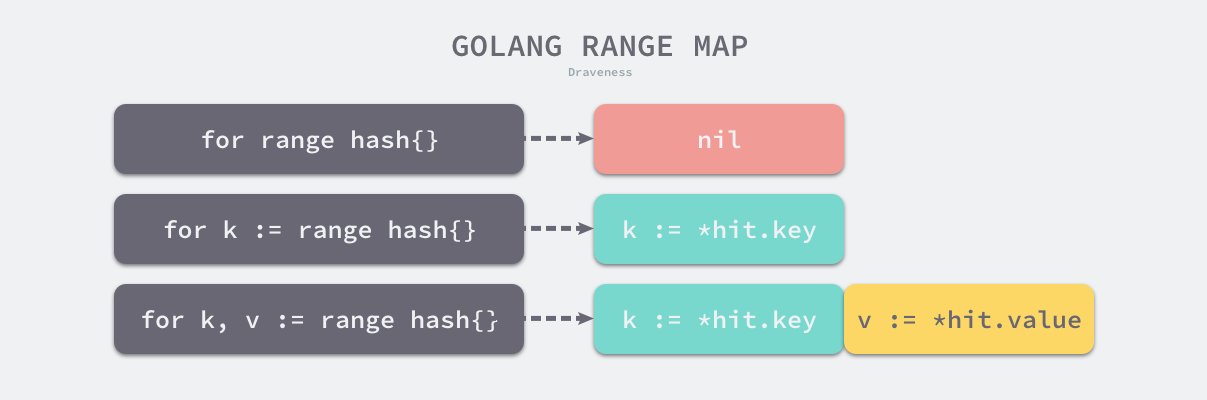
for-range遍历哈希表有三种不同形式:
for range m {}for k := range m{}for k, v := range m{}
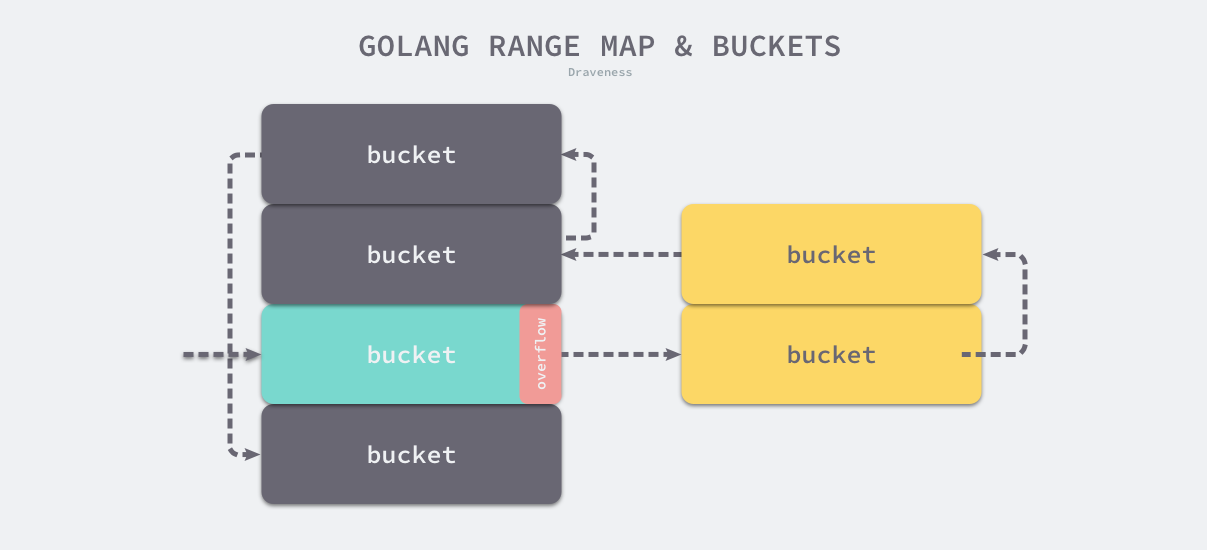
遍历哈希表时,桶的选择是随机的:
func mapiterinit(t *maptype, h *hmap, it *hiter) {
it.t = t
it.h = h
it.B = h.B
it.buckets = h.buckets
r := uintptr(fastrand())
it.startBucket = r & bucketMask(h.B)
it.offset = uint8(r >> h.B & (bucketCnt - 1))
it.bucket = it.startBucket
mapiternext(it)
}
使用了runtime.fastrand来随机选取桶的索引。
遍历哈希表的顺序:
- 先遍历正常桶及其溢出桶
- 然后遍历其他位置的桶
字符串
for-range遍历字符串有三种形式:
for range s{}for i := range s{}for i, c := range s{}
当使用for i, c := range s{}时:
ha := s
for hv1 := 0; hv1 < len(ha); {
hv1t := hv1
hv2 := rune(ha[hv1])
if hv2 < utf8.RuneSelf {
hv1++
} else {
hv2, hv1 = decoderune(ha, hv1)
}
v1, v2 = hv1t, hv2
}
c的是字符串的一个字符,类型为rune:
- 若
c只有一个字节,直接进行类型转换 - 若
c不只有一个字节,则需要runtime.decoderune进行解码
channel
for-range遍历channel有两种形式:
for range ch{}for v := range ch{}
使用for v := range ch{}会转换成:
ha := a
hv1, hb := <-ha
for ; hb != false; hv1, hb = <-ha {
v1 := hv1
hv1 = nil
...
}
for-range会循环至通道被关闭。
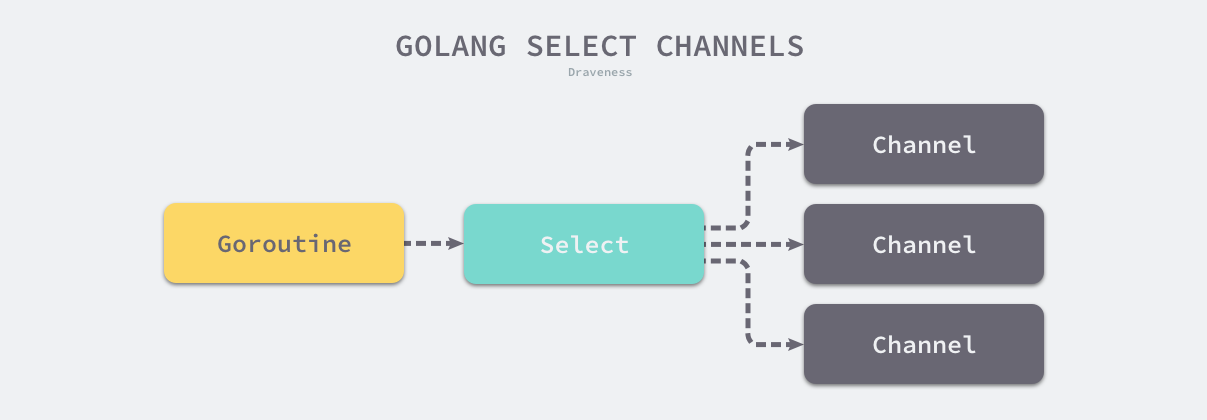
2. select
select用于监听多个channel是否可用:
- 若无可用通道,则阻塞当前goroutine
- 若有多个,则随机选择一个分支执行
- 若存在
default分支,则为非阻塞结构,无可用通道将直接执行default分支
2.1 数据结构
select无数据结构表示,但case分支可用runtime.scase表示:
type scase struct {
c *hchan // chan
elem unsafe.Pointer // data element
}
2.2 实现原理
select语句会在编译期间转换成OSELECT节点,每个OSELECT会持有一组OCASE节点,若OCASE执行条件为空则表示为default。
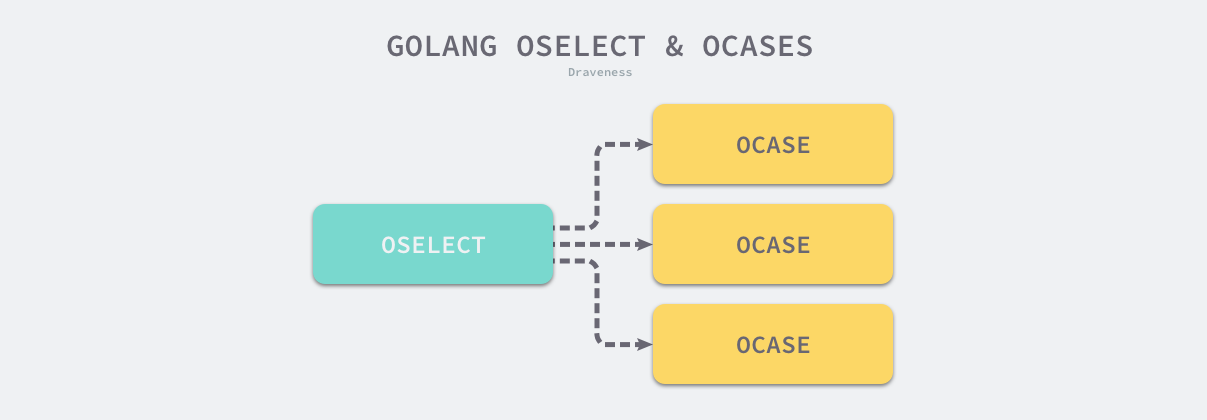
编译期
编译期根据select中的case数目不同,会有四种优化情况:
select不存在任何的case此时当前goroutine,将直接阻塞,永久休眠select只存在一个case转换成if语句:// 改写前 select { case v, ok <-ch: // case ch <- v ... } // 改写后 if ch == nil { block() } v, ok := <-ch // case ch <- v ...- 首先判断操作的 Channel 是不是空的
- 然后执行
case结构中的内容
select存在两个case,其中一个case是default此时为非阻塞结构,若channel不可用,直接执行defaultselect存在多个case默认情况下会通过runtime.selectgo获取执行case的索引,并通过多个if语句执行对应case中的代码
运行时
运行时执行编译期间展开的 runtime.selectgo 函数,该函数会按照以下的流程执行:
- 随机生成一个遍历的轮询顺序
pollOrder并根据 Channel 地址生成锁定顺序lockOrder - 根据
pollOrder遍历所有的case查看是否有可以立刻处理的 Channel:- 如果存在,直接获取
case对应的索引并返回 - 如果不存在,创建
runtime.sudog结构体,将当前 Goroutine 加入到所有相关 Channel 的收发队列,并调用runtime.gopark挂起当前 Goroutine 等待调度器的唤醒
- 如果存在,直接获取
- 当调度器唤醒当前 Goroutine 时,会再次按照
lockOrder遍历所有的case,从中查找需要被处理的runtime.sudog对应的索引
3. defer
defer使用时有三个关键点:
defer的调用时机:当前函数返回时defer的调用顺序:后进先出,后定义的defer先执行- 后调用的
defer函数会被追加到 Goroutine_defer链表的最前面 - 运行
runtime._defer时是从前到后依次执行
- 后调用的
defer的参数:defer的参数会在定义时预先进行拷贝,而不是在调用时处理- 调用
runtime.deferproc函数创建新的延迟调用时就会立刻拷贝函数的参数,函数的参数不会等到真正执行时计算
- 调用
3.1 数据结构
type _defer struct {
siz int32
started bool
openDefer bool
sp uintptr
pc uintptr
fn *funcval
_panic *_panic
link *_defer
...
}
defer函数以链表的形式组织在一起。
3.2 执行机制
defer的执行机制有三种:
- 堆分配,1.1 ~ 1.12
- 编译期将
defer关键字转换成runtime.deferproc并在调用defer关键字的函数返回之前插入runtime.deferreturn - 运行时调用
runtime.deferproc会将一个新的runtime._defer结构体追加到当前 Goroutine 的链表头 - 运行时调用
runtime.deferreturn会从 Goroutine 的链表中取出runtime._defer结构并依次执行
- 编译期将
- 栈分配,1.13
- 当该关键字在函数体中最多执行一次时,编译期间的
cmd/compile/internal/gc.state.call会将结构体分配到栈上并调用runtime.deferprocStack
- 当该关键字在函数体中最多执行一次时,编译期间的
- 开放编码,1.14
- 编译期间判断
defer关键字、return语句的个数确定是否开启开放编码优化; - 通过
deferBits和cmd/compile/internal/gc.openDeferInfo存储defer关键字的相关信息; - 如果
defer关键字的执行可以在编译期间确定,会在函数返回前直接插入相应的代码,否则会由运行时的runtime.deferreturn处理
- 编译期间判断
4. panic and recover
panic和recover的作用
panic能够改变程序的控制流,调用panic后会立刻停止执行当前函数的剩余代码,并在当前 Goroutine 中递归执行调用方的deferrecover可以中止panic造成的程序崩溃。只能在defer中发挥作用的函数,在其他作用域中调用不会发挥作用
panic 和 recover的执行有三个要点:
- panic 只会触发当前 goroutine 的 defer
- recover 只能在 defer 中生效
- panic 可以在 defer 中嵌套
4.1 数据结构
type _panic struct {
argp unsafe.Pointer
arg interface{}
link *_panic
recovered bool
aborted bool
pc uintptr
sp unsafe.Pointer
goexit bool
}
panic可以被连续调用,多个panic之间组成链表。
4.2 执行流程
panic和recover的流程如下:
- 编译器会负责做转换关键字的工作;
- 将
panic和recover分别转换成runtime.gopanic和runtime.gorecover; - 将
defer转换成runtime.deferproc函数; - 在调用
defer的函数末尾调用runtime.deferreturn函数
- 将
- 在运行过程中遇到
runtime.gopanic方法时,会从 Goroutine 的链表依次取出runtime._defer结构体并执行 - 如果调用延迟执行函数时遇到了
runtime.gorecover就会将_panic.recovered标记成 true 并返回panic的参数- 在这次调用结束之后,
runtime.gopanic会从runtime._defer结构体中取出程序计数器pc和栈指针sp并调用runtime.recovery函数进行恢复程序; runtime.recovery会根据传入的pc和sp跳转回runtime.deferproc;- 编译器自动生成的代码会发现
runtime.deferproc的返回值不为 0,这时会跳回runtime.deferreturn并恢复到正常的执行流程
- 在这次调用结束之后,
- 如果没有遇到
runtime.gorecover就会依次遍历所有的runtime._defer,并在最后调用runtime.fatalpanic中止程序、打印panic的参数并返回错误码 2
5. make and new
make 和 new 的作用:
make的作用是初始化内置的数据结构,切片、哈希表和 Channelnew的作用是根据传入的类型分配一片内存空间并返回指向这片内存空间的指针
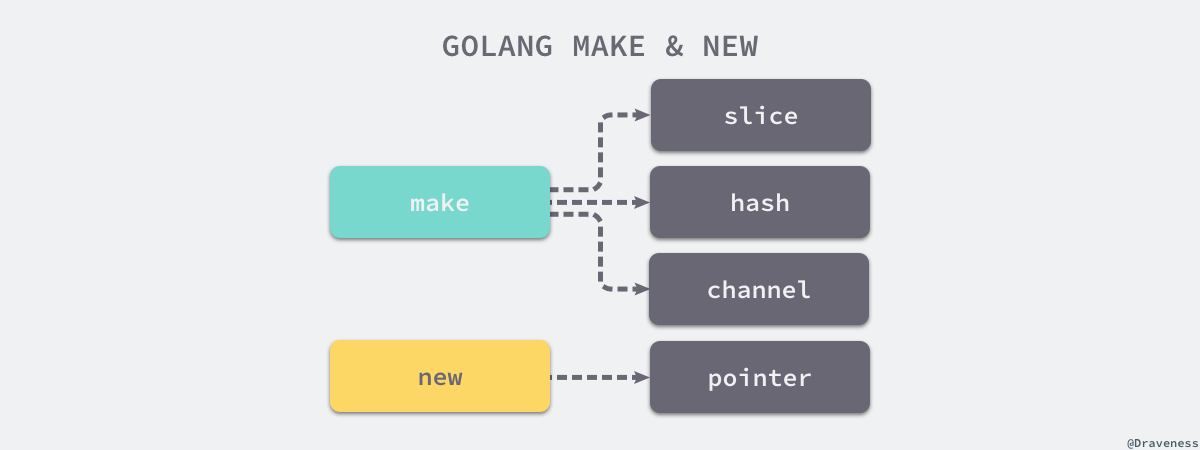
5.1 make
编译期会将make转换成不同的节点:
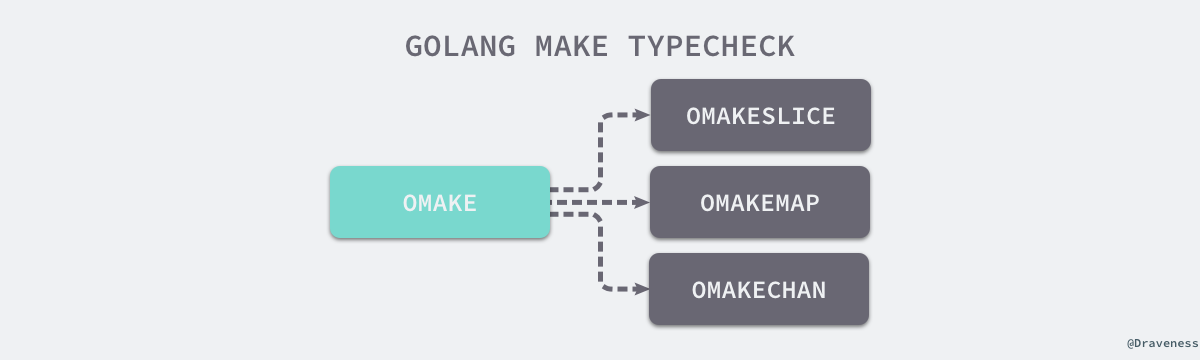
后序将会调用不同的初始化函数执行。
5.2 new
编译器会在中间代码生成阶段通过以下两个函数处理该关键字:
cmd/compile/internal/gc.callnew会将关键字转换成ONEWOBJ类型的节点cmd/compile/internal/gc.state.expr会根据申请空间的大小分两种情况处理:
- 如果申请的空间为 0,就会返回一个表示空指针的
zerobase变量; - 在遇到其他情况时会将关键字转换成
runtime.newobject函数,会获取传入类型占用空间的大小,调用runtime.mallocgc在堆上申请一片内存空间并返回指向这片内存空间的指针
- 如果申请的空间为 0,就会返回一个表示空指针的