
5.1 for and range
Golang 中的循环有两种:
forfor-range
for-range在编译时将会被转换成普通的for循环,在最终编译的汇编中的结构是相同的。
5.1.1 现象
循环永动机
func main() {
arr := []int{1, 2, 3}
for _, v := range arr {
arr = append(arr, v)
}
fmt.Println(arr)
}
$ go run main.go
1 2 3 1 2 3
若遍历切片时,在循环体中为切片追加元素,不会改变循环次数。
神奇的指针
func main() {
arr := []int{1, 2, 3}
newArr := []*int{}
for _, v := range arr {
newArr = append(newArr, &v)
}
for _, v := range newArr {
fmt.Println(*v)
}
}
$ go run main.go
3 3 3
若在循环体中获取i, v := range中的&v将会得到预期之外的结果。
清空
func main() {
arr := []int{1, 2, 3}
for i, _ := range arr {
arr[i] = 0
}
}
依次遍历数组/切片/哈希表的元素,将其置为0时非常耗时的。此操作在编译时将会优化为清空整片内存中的内容。
"".main STEXT size=93 args=0x0 locals=0x30
0x0000 00000 (main.go:3) TEXT "".main(SB), $48-0
...
0x001d 00029 (main.go:4) MOVQ "".statictmp_0(SB), AX
0x0024 00036 (main.go:4) MOVQ AX, ""..autotmp_3+16(SP)
0x0029 00041 (main.go:4) MOVUPS "".statictmp_0+8(SB), X0
0x0030 00048 (main.go:4) MOVUPS X0, ""..autotmp_3+24(SP)
0x0035 00053 (main.go:5) PCDATA $2, $1
0x0035 00053 (main.go:5) LEAQ ""..autotmp_3+16(SP), AX
0x003a 00058 (main.go:5) PCDATA $2, $0
0x003a 00058 (main.go:5) MOVQ AX, (SP)
0x003e 00062 (main.go:5) MOVQ $24, 8(SP)
0x0047 00071 (main.go:5) CALL runtime.memclrNoHeapPointers(SB)
...
其中编译器会直接使用 runtime.memclrNoHeapPointers 清空切片中的数据。
哈希表的随机遍历
func main() {
hash := map[string]int{
"1": 1,
"2": 2,
"3": 3,
}
for k, v := range hash {
println(k, v)
}
}
上述代码在运行时可能输出的结果顺序完全不同。
5.1.2 for
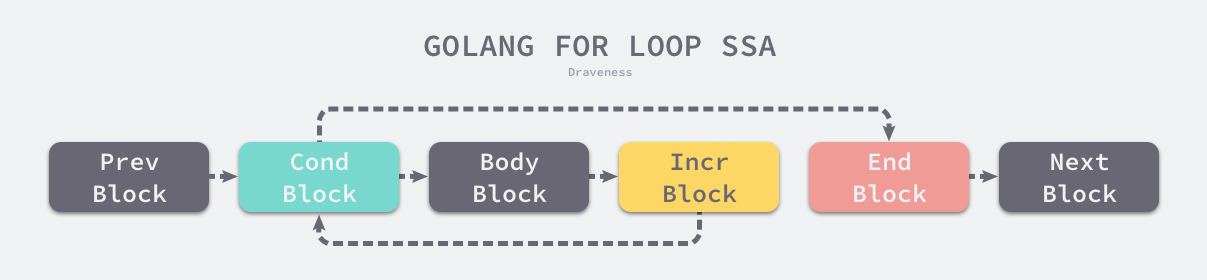
for循环被编译器视作OFOR类型的节点,由四个部分组成:
Ninit:循环初始化Left:循环执行条件Right:循环体结束后执行的操作NBody:循环体
for Ninit; Left; Right {
NBody
}
在 SSA 中间代码的生成阶段,for循环会被转换成如下结构:
5.1.3 for-range
对于for-range,编译器会将ORANGE节点转换成OFOR节点:

数组和切片
for-range遍历数组和切片时,cmd/compile/internal/gc.walkrange会将其转换成不同的控制逻辑:
- 分析遍历数组和切片清空元素的情况;
- 分析使用
for range a {}遍历数组和切片,不关心索引和数据的情况 - 分析使用
for i := range a {}遍历数组和切片,只关心索引的情况 - 分析使用
for i, elem := range a {}遍历数组和切片,关心索引和数据的情况
遍历清空元素
func walkrange(n *Node) *Node {
switch t.Etype {
case TARRAY, TSLICE:
if arrayClear(n, v1, v2, a) {
return n
}
cmd/compile/internal/gc.arrayClear会优化 Go 语言遍历数组或者切片并删除全部元素的逻辑:
// 原代码
for i := range a {
a[i] = zero
}
// 优化后
if len(a) != 0 {
hp = &a[0]
hn = len(a)*sizeof(elem(a))
memclrNoHeapPointers(hp, hn)
i = len(a) - 1
}
此时会使用 runtime.memclrNoHeapPointers 或者 runtime.memclrHasPointers 清除目标数组内存空间中的全部数据,并在执行完成后更新遍历数组的索引。
for range a
ha := a
hv1 := temp(types.Types[TINT])
hn := temp(types.Types[TINT])
init = append(init, nod(OAS, hv1, nil))
init = append(init, nod(OAS, hn, nod(OLEN, ha, nil)))
n.Left = nod(OLT, hv1, hn)
n.Right = nod(OAS, hv1, nod(OADD, hv1, nodintconst(1)))
if v1 == nil {
break
}
当循环形式为for range a时,满足v1 == nil,此时循环会被转换成:
ha := a
hv1 := 0
hn := len(ha)
v1 := hv1
for ; hv1 < hn; hv1++ {
...
}
for i := range a
if v2 == nil {
body = []*Node{nod(OAS, v1, hv1)}
break
}
此时满足v2 == nil,此时循环会被转换成:
ha := a
hv1 := 0
hn := len(ha)
v1 := hv1
for ; hv1 < hn; hv1++ {
v1 = hv1
...
}
这种形式将会记录遍历时的索引。
for i, v := range a
tmp := nod(OINDEX, ha, hv1)
tmp.SetBounded(true)
a := nod(OAS2, nil, nil)
a.List.Set2(v1, v2)
a.Rlist.Set2(hv1, tmp)
body = []*Node{a}
}
n.Ninit.Append(init...)
n.Nbody.Prepend(body...)
return n
}
此时i, v都需要,那么会被转换成:
ha := a
hv1 := 0
hn := len(ha)
v1 := hv1
v2 := nil
for ; hv1 < hn; hv1++ {
tmp := ha[hv1]
v1, v2 = hv1, tmp
...
}
对于上述所有形式的for-range结构:
ha:原切片的拷贝hn:记录了切片的长度v2:在每次循环时,会被重新赋值,其地址并不会发生改变
所以有:
- 在循环期间为切片追加元素并不会改变循环次数
- 若获取
&v,因其地址是不变的,其值会是循环结束时赋予的最后一个值
哈希表
遍历哈希表时,编译器会使用 runtime.mapiterinit 和 runtime.mapiternext 两个运行时函数重写原始的 for-range 循环:
// for key, val := range hash {}
ha := a
hit := hiter(n.Type)
th := hit.Type
mapiterinit(typename(t), ha, &hit)
for ; hit.key != nil; mapiternext(&hit) {
key := *hit.key
val := *hit.val
}
cmd/compile/internal/gc.walkrange 处理 TMAP 节点时,编译器会根据 range 返回值的数量在循环体中插入需要的赋值语句:

遍历哈希表时会使用 runtime.mapiterinit 函数初始化遍历开始的元素:
func mapiterinit(t *maptype, h *hmap, it *hiter) {
it.t = t
it.h = h
it.B = h.B
it.buckets = h.buckets
r := uintptr(fastrand())
it.startBucket = r & bucketMask(h.B)
it.offset = uint8(r >> h.B & (bucketCnt - 1))
it.bucket = it.startBucket
mapiternext(it)
}
- 初始化
runtime.hiter结构体中的字段 - 通过
runtime.fastrand生成一个随机数,随机选择一个遍历桶的起始位置
遍历时使用 runtime.mapiternext:
func mapiternext(it *hiter) {
h := it.h
t := it.t
bucket := it.bucket
b := it.bptr
i := it.i
alg := t.key.alg
next:
if b == nil {
if bucket == it.startBucket && it.wrapped {
it.key = nil
it.value = nil
return
}
b = (*bmap)(add(it.buckets, bucket*uintptr(t.bucketsize)))
bucket++
if bucket == bucketShift(it.B) {
bucket = 0
it.wrapped = true
}
i = 0
}
- 待遍历的桶为空时,选择需要遍历的新桶
- 不存在待遍历的桶时,返回
(nil, nil)键值对并中止遍历
for ; i < bucketCnt; i++ {
offi := (i + it.offset) & (bucketCnt - 1)
k := add(unsafe.Pointer(b), dataOffset+uintptr(offi)*uintptr(t.keysize))
v := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+uintptr(offi)*uintptr(t.valuesize))
if (b.tophash[offi] != evacuatedX && b.tophash[offi] != evacuatedY) ||
!(t.reflexivekey() || alg.equal(k, k)) {
it.key = k
it.value = v
} else {
rk, rv := mapaccessK(t, h, k)
it.key = rk
it.value = rv
}
it.bucket = bucket
it.i = i + 1
return
}
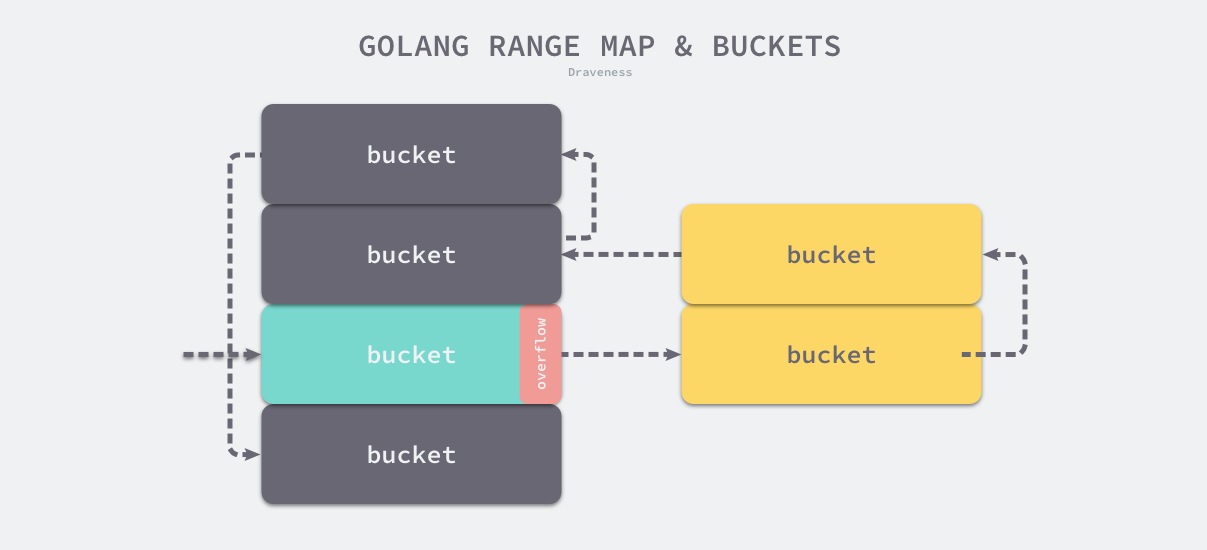
b = b.overflow(t)
i = 0
goto next
}
- 从桶中找到下一个遍历的元素,
- 若哈希表处于扩容期间就会调用
runtime.mapaccessK获取键值对
遍历了正常桶后,会通过 runtime.bmap.overflow 遍历哈希中的溢出桶。
字符串
遍历时会获取字符串中索引对应的字节并将字节转换成 rune。
for i, r := range s {} 的结构会被转换成:
ha := s
for hv1 := 0; hv1 < len(ha); {
hv1t := hv1
hv2 := rune(ha[hv1])
if hv2 < utf8.RuneSelf {
hv1++
} else {
hv2, hv1 = decoderune(ha, hv1)
}
v1, v2 = hv1t, hv2
}
- 当前
rune是 ASCII 的,占用一个字节,只需要将索引加一 - 当前
rune占用了多个字节就会使用runtime.decoderune函数解码
通道
for v := range ch {} 的语句最终会被转换成:
ha := a
hv1, hb := <-ha
for ; hb != false; hv1, hb = <-ha {
v1 := hv1
hv1 = nil
...
}
使用 <-ch 从管道中取出等待处理的值,这个操作会调用 runtime.chanrecv2 并阻塞当前的协程,当 runtime.chanrecv2 返回时会根据布尔值 hb 判断当前的值是否存在:
- 如果不存在当前值,意味着当前的管道已经被关闭
- 如果存在当前值,会为
v1赋值并清除hv1变量中的数据,然后重新陷入阻塞等待新数据